 Linuxeden开源社区
Linuxeden开源社区作者
同程旅游 (LY.COM) 是一家专业的一站式旅游预订平台,提供近万家景点门票、特价机票、出国旅游、周边游、自驾游及酒店预订服务 ; 专业旅游线路服务。全年公司服务人次超过 3 亿。目前同程旅游各个业务线,如:国内国际酒店,机票,火车票,会员,商业智能,分析等等都使用实时计算平台来构建实时类系统。
本文以时间为线索来介绍我们在实时计算平台建设过程中做过的工作,遇到的问题,希望能给需要实时计算的公司和同学提供参考。
第一个实时应用
在 2014 年中,为了能够采集到用户在 PC,APP 等平台上的行为轨迹,我们开始开发实时应用。那个时候可选的技术架构还是比较少的,实时计算框架这块,当时比较主流的有 Storm 和 Spark-streaming。综合考虑实时性,接入难度。我们最终选择使用 Tengine + Flume + Kafka + Storm 作为核心的架构。
简单介绍下 Storm:Apache Storm 是一个分布式的实时计算框架,可以很方便地对流式数据进行实时处理和分析,能运用在实时分析、在线数据挖掘、持续计算以及分布式 RPC 等场景下。Storm 的实时性可以使得数据从收集到处理展示在秒级别内完成。
我们基于 Storm0.9.4 构建了第一个版本的用户行为轨迹采集框架。PC,APP 页面上的埋点数据通过 Tengine 日志记录下来后,Flume 将用户轨迹数据采集到 Kafka 消息队列中缓存,最后通过 Storm 实时处理,分发到外部存储如:HDFS,Hbase,ElasticSearch。从而为业务方提供离线或近实时的数据支持。
实时计算平台建设
后来随着实时应用的增多,我们开始着手建设一个实时计算平台来更好的为业务提供支持。平台建设中主要有两个核心目标:易用性 + 稳定性。
易用性
当 Storm 已经成为流计算的标配,基于 Storm 的数据清洗、日志分析、用户轨迹 、实时报表、实时监控、价格计算 等应用愈来愈多时,用户的痛点也逐渐多起来:Topology 开发的门槛较高、高吞吐量的应用调优困难、开发调试周期长。这种情况下,如果能使用类 SQL 描述业务的实时计算的需求,并将类 SQL 转化为基于 storm 的 topology。就能够简化使用,降低业务接入难度。
在 CEP(Complex Event Processing) 中,有很多开源的 CQL 的实现,如: Esper、 Siddhi、Squall。但是这些开源实现都有一些问题:不算是全部的 CQL 语句,即仅仅使用 CQL 语句还不能运行,还必须依靠一些客户端的代码。 这样就给使用带来了一些不便, 用户必须学习客户端 API,比较繁琐,上手难度也比较大。
我们关注到华为开源的 StreamCQL 可以将 CQL 直接转化成为 Storm Topology。而 Storm1.0 之后加入了 SQL 层,提供了 StormSQL,可以将 SQL 转化成为 Storm 的 Topology。
两者的执行流程分别如下:
(点击放大图像)
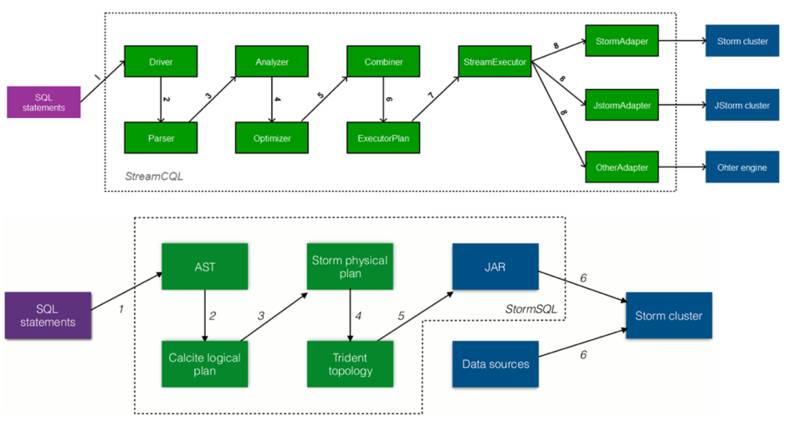
通过比较,华为 StreamCQL 可以和集群的耦合比较低,比较容易扩展,并且可以通过增加 Adapter 的方式适配不同的执行引擎。
最后我们在实时计算平台集成 StreamCQL 的 Client,将用户提交的 CQL 语句解析后提交到 Storm 集群。
StreamCQL 投入线上作为生产环境使用时,根据实际业务需要,我们完成如下功能开发。
- 支持同程的 TurboMQ 作为 Source
- 支持字段属性大小写敏感
- 增加 JsonSerDe 作为序列化方式
- 增加 HDFS,ElasticSearch 等作为数据输出的 Sink
- 自定义 SimpleSerDe 支持动态列数量
- 开发完成了一部分 UDF
- 兼容适配 storm1.0.1 版本
引入 StreamCQL 后,解决了一部分 BI 及数据分析同学的痛点,通过类 SQL 语言使得基于实时计算平台的应用开发变得快速及简单。
能不能做的更易用?我们在 StreamCQL 的基础上将一部分常用的算子及数据源再次进行了封装 ,通过解析控件的关联关系,配置参数的识别从而提供基于图形控件配置的 ETL 任务,零基础的用户也可以进行可视化的拖拽操作,更加灵活的配置常用的数据清洗等业务。
(点击放大图像)
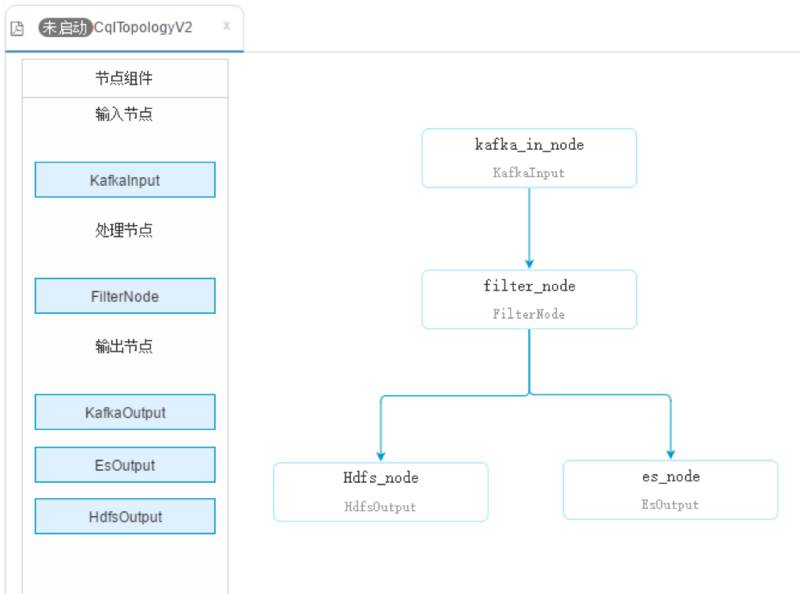
稳定性
实时应用和离线应用相当大的不同就是实时任务不是定时调起,而是作为一个长服务需要一直稳定的运行。那么对于实时平台的稳定性就有相当高的要求。
我们从以下几个方向来保证平台服务的稳定性:
- 监控
- 告警
- 异常处理
- 日志回溯
监控,这块我们分别从对硬件和软件两个方面对集群进行监控。
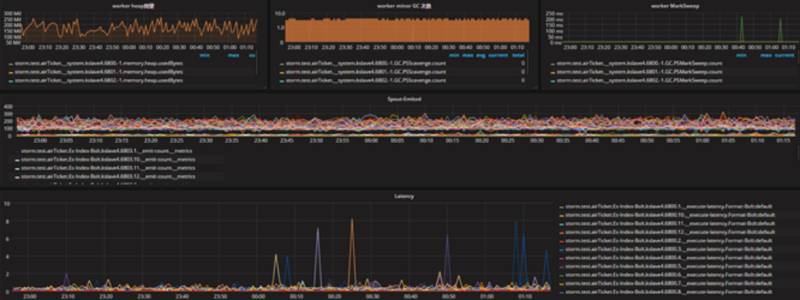
对于硬件资源如:CPU,内存,IO 等等使用 zabbix 进行监控。对于集群资源使用 grafana+graphite+ carbon+ whisper 进程监控。通过使用开发统一的自定义 MetricsConsumer 收集 Storm 的 Topology 运行时 Acked,Failed,Latency 等信息。能够清晰监控出实时应用数据处理,延迟等情况。
监控实施过程中也遇到一些问题,随着监控指标和应用的增多,单节点 graphite 的读写性能有些下降,我们先通过降低 Topology 的 Metric 收集上报频率来优化。并调整监控数据存储的有效期。随后将 Metric 存储迁移至 OpenTSDB 这个时间序列数据库。
(点击放大图像)
告警,这部分基于上面监控的数据进行告警,对于数据延迟,数据处理失败,worker 重启等多种异常情况进行告警(邮件,短信)。告警实施过程中要配置好告警信息的通知策略:
一是要控制单个实时应用告警信息发送频率,当单个应用发生异常时,在应用恢复时间内,避免大量的重复告警信息发送打扰用户 。
二是对于重要性不同的异常,设置不同的告警频率,防止频繁的告警导致开发同事会忽略某些重要告警信息。
异常处理,在 storm 中,nimbus 节点和 supervisor 节点 主要负责任务的分发管理,状态监控,worker 启停。一旦 Topology 任务提交执行成功后,即使 nimbus 和 supervisor 进程都挂掉,短时间内也不会影响 worker 的正常的运行。但是再 worker 发生异常时,仍需要存活的主从节点重新拉起 worker。所以我们编写监控脚本监控 nimbus 和 supervisor 的进程退出异常,当异常发生时,脚本重新拉起 nimbus 和 supervisor 进程。并发送告警信息。
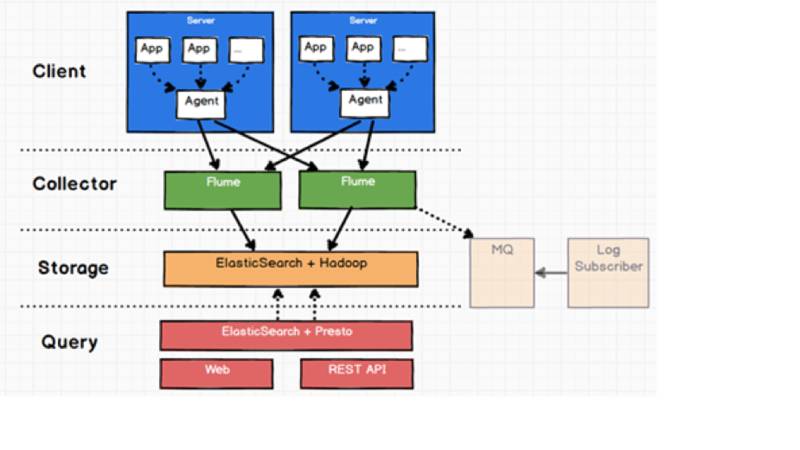
日志收集,Storm 的分布式日志查看不是很方便,并且当 worker 重启时,日志会打在其它 Slot 对应的 worker.log 上追加,导致日志混杂在一起。不方便用户查看。
最早通过 Flume + ElasticSearch 将不同 worker 节点的日志收集至 ES 中供用户查看。后来随着日志量的增加,我们便开始接入同程内部的天网日志收集系统,对日志的冷热数据分离,将历史归档数据日志数据存入 HDFS,热数据存入 ES。
(点击放大图像)
实时计算框架版本升级
最早使用的 storm 集群使用的 0.9.4 版本。随着集群规模的增加以及应用的增多,发现该版本有一些问题无法解决。如:
- 没有基于 eventTime 滑动时间窗口 API 支持,实现一些要求较高实时监控项目比较困难
- 读写流量不好控制,一旦下游数据处理变缓慢时,有可能造成 OOM
于是在 2016 年的这个时候,我们开始着手升级 storm 版本,升级到 Storm 1.0.1 。Storm1.0 新版本提供的特性还是很多的,主要有这三个特性是我们急需的:时间窗口相关 API 的支持、反压机制、nimbus HA。
升级过程中我们最关心的是升级代价怎么样,因为当前接入的业务比较多,升级复杂程度直接影响稳定性。
由于 storm0.9.4 版本很多包名是 backtype.storm,而 storm1.0 之后都更换为 org.apache.storm。社区也考虑到这点,所以在从 0.x 版本升级到 1. x 版本时 Storm 提供了一个集群的配置项来应对这一问题,可以通过新增配置 client.jartransformer.class:”org.apache.storm.hack.StormShadeTransformer”来完成平滑的迁移。
在这里分享下 storm1.0.1 的使用过程中我们遇到的坑,大家可以参考下:
storm-1879 :
在启动 Topology 的时候发现有些空的 slot 端口被占用,原因可能是在 Kill Topology 的时候,Supervisor 关闭 worker 和删除资源文件时产生冲突,导致 kill worker 失败,worker 的僵尸进程会一直占用 slot 端口。
解决方案:小版本升级 storm1.0.3
storm-2440 :
KafkaSpout 在从 kafka 读取数据的时候,当 kafka broker 出现异常挂掉时,KafkaSpout 中的 SimpleConsumer 在 fetch 数据时会抛出 SocketTimeoutException,KafkaSpout 需要捕获该异常,并重建连接。而 Storm1.0 中的 executor 线程并没有捕获该异常,直接导致当 kafka broker 挂掉时,该 executor 停止消费 kafka 的 partition,不会恢复。
解决方案: 这个问题在当前 1. x 版本都存在,需要自己把该 issue 对应的 patch 打上,重新编译。
正在做的事情
如果不使用 Trident 时,Storm 无法保证数据处理的 Exactly Once,因此今年我们尝试了 Flink。Flink 和 Spark 一样拥有 checkpoint 机制。在遇到程序故障时(如机器、网络、软件等故障),Flink 停止分布式数据流。系统重启所有 operator ,重置其到最近成功的 checkpoint。输入重置到相应的状态快照位置。保证被重启的并行数据流中处理的任何一个 record 都不是 checkpoint 状态之前的一部分。并在一些实时订单数据清洗,资源价格计算等有关的实时应用中,我们尝试使用 Flink 来达到 Exactly Once,在数据处理延迟较低的情况下拥有很好的吞吐量。
目前我们在实时计算平台提供了 Storm,Flink,Spark Streaming,在日常的业务开发中,开发人员可能对于提供的三种实时框架难以全部掌握或开发中需要关注各自框架上的 API 细节太多。因此很多情况下需要会来寻求资深的支持。我们想,能不能尽量统一 API,屏蔽各自框架细节底层。所以我们正在调研 Apache Beam,Beam 提供了一次编写、多个不同引擎到处运行的特性。目前 Beam 对于 Flink 的支持最好,而对 Spark Streaming 也有较为不错的支持。目前我们组正在开发 Beam 的 Storm Runner,尽量提供 Beam 对 Storm 的支持。
以上就是我要分享的内容,在结尾处,我简单总结一下我们的整体架构:
(点击放大图像)
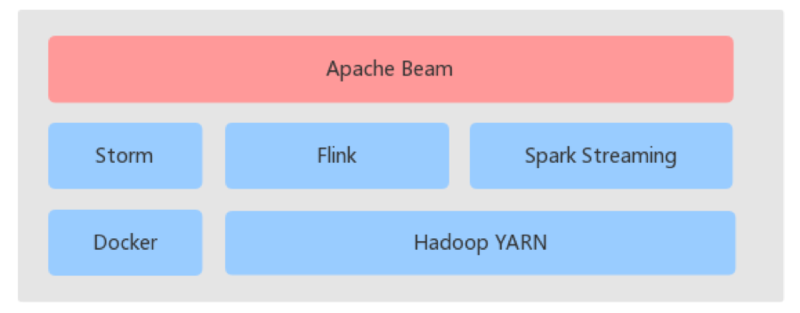
基于 YARN 提供 Flink 和 Spark Streaming,通过 Storm on Docker 提供 storm 集群的资源隔离。并尝试通过 Apache Beam 来完成面向开发人员的 SDK 统一。虽然目前对部分计算框架支持不理想,但这是未来的方向,值得我们去尝试。
作者介绍
李苏兴,同程旅游大数据研发部高级工程师,实时计算平台负责人。
转自 http://www.infoq.com/cn/articles/evolution-of-tongcheng-real-time-computing