 Linuxeden开源社区
Linuxeden开源社区就像发展迅速的技术一样,AI也激发了大规模的FOMO(害怕错过)、FUD(恐、惑、疑)和不和。其中一些是应该的,也有一些不是——但这个行业正在留意。从秘密的硬件初创企业到金融技术巨头乃至于上市公司,各个团队都在忙碌地实施自己的AI战略。这一切都归结到一个关键且高风险的问题:“我们会怎么使用AI和机器学习来让我们做的事情变得更好?”
通常公司都还没有为AI做好准备。也许他们招聘了自己的第一位数据科学家但却达不到想要的效果,或者也许数据素养并不是他们文化的核心。但最常见的情形是透明还没有建立起基础而设施去实施最基本的数据科学算法和操作,更不用说机器学习了。
作为数据科学/AI顾问,我必须无数次地传达这一信息,过去2年尤其如此。其他人也表示同意。在大家都对你所在的领域充满着兴奋之情是做一个泼冷水的人是很困难的,尤其是如果你也分享着这种兴奋时。还有你应该怎么去告诉那些公司,说如果没有(或者成为)精英——也就是自我任命的看门人的话是不可能为AI做好准备的呢?
这里是一个引起大家最多共鸣的一个解释:
可以把AI看作是需求金字塔的顶端。是的,自我实现(AI)是非常棒的,但你首先需要食物、水和庇护所(数据素养、数据采集和基础设施)。
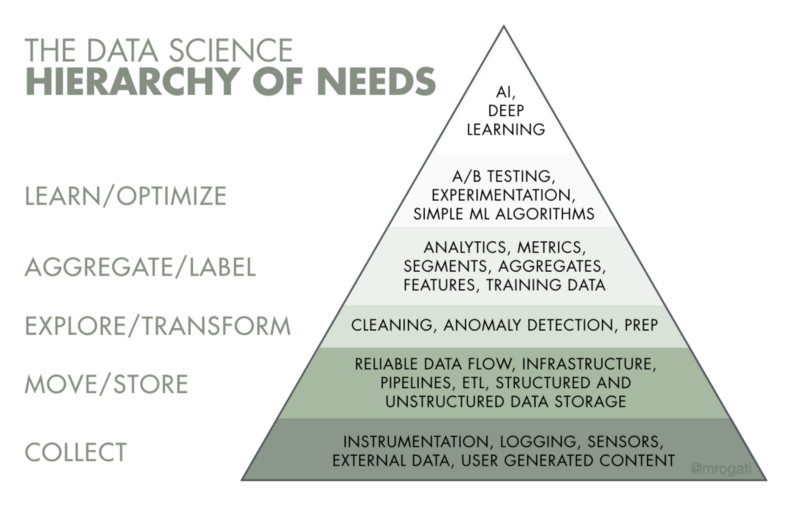
你的数据需要有牢靠的基础,然后才可以高效地运用AI和机器学习。
基本需求:你能算吗?
金字塔的底部是数据采集。你需要什么样的数据?你又有什么样的数据?如果是面向用户的产品,你有没有记录所有相关的用户交互?如果产品是传感器,数据是从哪儿来的,怎么来?记录一种尚未物联化的交互有多容易?毕竟,拥有合适的数据集是机器学习最近能取得进展的关键。
其次,要弄清楚数据流是如何流经系统的?你有没有可靠的数据流处理系统或者ETL(提取转换加载)?数据存放在哪里?访问和分析这些数据有多容易?Jay Kreps一直都在说(有10年的时间了)可靠的数据流是任何数据处理方面事情的关键。(附注:我正在寻找这句话的确切出处,结果在他的硕士论文《我喜欢日志》中找到了。然后我注意到他在一段话之后做出了这个马斯洛的需求层次论的比较,并以“值得注意的是”来作为附注。说到相关工作,后来我又看到了Hilary Mason和Chris Wiggings的精彩文章,讲的是数据科学家应该做什么事情。几天前,Sean Taylor披露了自己的数据科学需求金字塔,当然这跟这里的金字塔是完全不同的。)
只有当你有了数据之后,才可以对数据进行探索和转换。这里的工作包括臭名卓著的“数据清洗”,这是数据科学领域被低估的一项工作,这一块我得另起一篇文章来谈。当你发现你失去了一大块数据,你的传感器不可靠,某次版本变更意味着你的事件被丢失,你对某个标志产生了误解时——你就得回过头来确保金字塔的基础是牢靠的。
当你可以可靠地探索和清洗数据时,你就可以进行传统上被认为是BI或分析方面的事情:定义要跟踪的指标,其季候性以及对不同因素的敏感性。也需要进行一些艰苦的用户细分的工作,去看看会不会有什么东西冒出来。然而,既然你的目标是AI,你现在要搭建的是随后被认为是特征的东西,以供将来吸收进你的机器学习模型里面。在这个阶段,你还知道了你打算要预测或者学习什么,你还可以开始通过生成标签(自动或者手工的方式)来准备你的训练数据。
这个阶段也是你找到自己最令人兴奋和引人注目的数据故事的时候——但这也是另一篇文章的主题了。
好了,现在我能算了。接下来呢?
我们有了训练数据了——那是不是现在可以进行机器学习了呢?也许吧,如果你是想在内部进行客户流失率预测的话;但如果结果是面向客户的答案就是否定的。我们需要进行A/B测试(不管是如何的原始)或者有准备好的实验框架,这样才能逐步部署以避免灾难,并在改变影响每个人之前对改变的效果进行粗略的估计。这也是将非常简单的基线部署到位的合适时机(对于推荐系统来说,基线系统可以是“最热门”,然后是“细分用户市场的最热门”——这就是非常烦人但有效的“个性化之前先用老一套”)。
简单的启发法的难以击败甚至到令人惊讶的地步,它们会让你以端到端的方式调试系统,这不需要神秘的机器学习黑箱,在这中间要需要超参数调整。
到了这个时候,你可以部署一个非常简单的机器学习算法(比如逻辑回归或者分类等),然后考虑可能影响到你的结果的信号和特征。天气和普查数据是我的目标。还有,尽管深度学习很强大,但它不会自动帮你做这些事情。引入新的信号(特征建立,不是特征工程)可以大幅改善你的性能。在这里花些时间是值得的,即便身为数据科学家我们也对向上进入金字塔的更高层面感到兴奋。
发展AI!
数据有了。装置也有了。你的ETL开始发挥作用了。你的数据已经组织好并且清洗过了。你有了仪表盘,标签以及好的特征。你在测量合适的东西。你可以每天进行试验。你有了一个基线算法,可以进行端到端的调试,并且在生产中运转——而且你已经对它进行了十几次的变更。总之,你已经准备好了。接下来从自己铺开到利用专长于机器学习的公司,你可以继续去尝试最新最好的东西。你可能可以在生产方面取得巨大改进,或者也许不能。但最坏的情况下,你也能学到一些新的方法,形成自己的观点并有了上手体验,并且可以告诉你的投资者和客户自己在AI方面做了哪些努力而不是给人感觉像是个骗子。而在最好的情况下,你可以为用户、客户和公司带来巨大的不同——这是机器学习的一个真正的成功故事。
等一下,MVP、敏捷、精益等其他东西呢?
数据科学需求层次轮不是用1年的时间过度建设脱节的基础设施的借口。就像传统的最小可行产品(MVP)的开发套路一样,你也要从产品小的垂直板块开始,把它从端到端都做好了。比方说,在Jawbone,我们先从睡眠数据开始并搭建它的金字塔:工具手段,ETL,清洗和组织,标签捕捉和定义,指标(大家美军每晚的睡眠时间是多长?小憩呢?什么是小憩?),跨细分市场分析,一直到数据故事和机器学习驱动数据产品(自动睡眠检测)。我们后来又把它延伸到步数,然后食物、天气、锻炼、社交网络以及沟通——每次做一个。在端到端做完一件事情之前我们并没有建设一个包罗万象的基础设施。
提出合适的问题,开发合适的产品
这只与如何可以有关,跟应该如何无关(出于实用主义或者道德伦理的原因)。
机器学习工具的希望
“等一下,Amazon API或者TensorFlow等别的开源库呢?其他在卖机器学习或者自动析取洞察和特征的工具的公司呢?”
所有这些都很出色很有用(一些公司最终的确煞费苦心地定制出来整个金字塔来展示自己的工作。这些人是英雄)。然而,鉴于当前AI炒作的强烈影响力,大家都试图把脏的、存在断层、跨越了数年且格式和意思不断改变的数据,那些尚未被理解的数据,那些结构化行不通的数据塞进去,还指望这些工具能够魔术般地处理好它们。也许将来有一天会是这种情况,我对朝着这个方向的努力举双手赞成。但在此之前,为你的AI金字塔打造好一个牢固的基础是值得的。
【编译组出品】
本文来自翻译:hackernoon.com,如若转载,请注明出处:http://36kr.com/p/5087801.html