 Linuxeden开源社区
Linuxeden开源社区对于企业来说,随着规模越来越大,整个系统中存在越来越多的子系统,每个子系统又被多个其他子系统依赖或者依赖于其他子系统。大部分系统在走到这一步的过程中,大概率会发生这样的场景:作为某个子系统的负责人或者 OnCall 人员,休息的时候都不安稳,心里老是忐忑着系统会不会挂。导致周末不敢长时间出门,晚上睡梦中被电话叫醒,痛苦不堪。
那么,在一个成熟的分布式系统中,我们该如何去保证它的可用性呢?迫切的需要解放我们紧绷的神经。下面,我们就来看下做高可用的思路和关键部分。
如何下手做高可用?
在这个时候,我们的系统全貌大致是这样的。
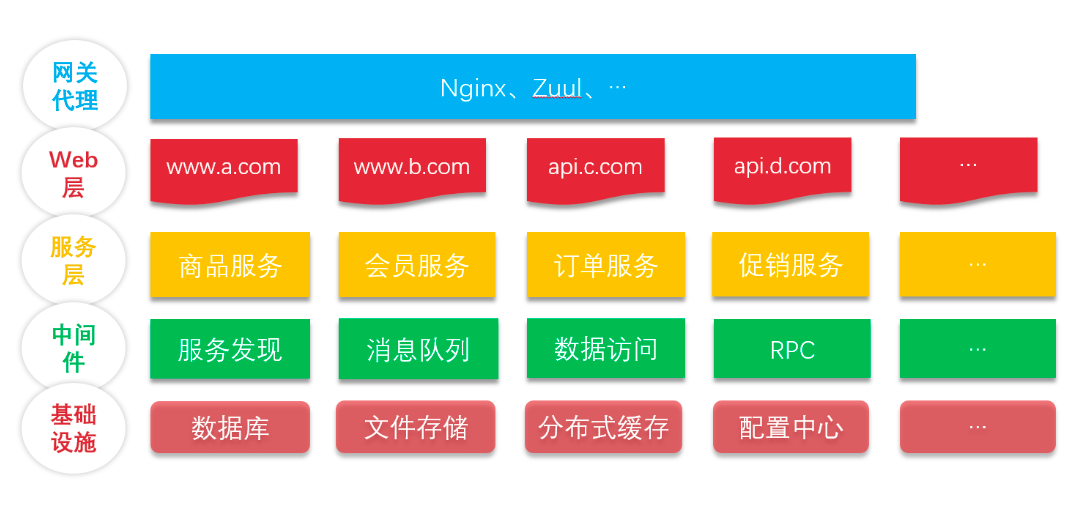
由大大小小的多个部分组合而成的一个完整系统,可以看到包含网关、Web 层、服务层、中间件、基础设施,这每一层之间又是层层依赖。在如此的一个庞然大物面前做高可用是一个系统化的工程,除了良好的顶层设计规划外,还需要深入到细节。由于雪崩效应的存在,软件系统是一个完美体现“千里之堤毁于蚁穴”的地方,一个小问题导致整个系统全盘崩塌的案例也不在少数。
所以,首先我们需要拥有保持怀疑的心态。这个怀疑是指对系统的怀疑,而不是对人的怀疑。人非圣贤孰能无过,况且写代码是一个精细活,还不是流水线式的那种。而且,哪怕不是写代码的疏忽,其他诸如网络、操作系统等异常,甚至一些恶意的攻击都会导致故障随时发生。
那么我们具体应该怎么做呢?既然故障导致了可用性降低,那么接下来的工作必然是围绕解决故障展开。分为 3 个步骤:故障发现、故障消除、故障善后。
故障发现
所谓“故障发现”,就是通过技术手段实时采集系统中每个节点的健康状态,以及每 2 个节点之间链路的健康状态,包括但不限于调用成功率、响应时间等等。借此代替我们的眼睛去盯着整个系统,一旦低于某个设定的阈值,就触发报警给我们一个提醒。因为当你的系统中存在成百上千的程序时,靠肉眼去找到发生故障的位置,简直是天方夜谭。哪怕找到了,也可能已经产生了巨大的损失。
负责故障发现的解决方案都属于应用性能管理(APM)范畴。我们在部署这个“眼睛”的时候,需要考虑到全方位的覆盖,要包含所有的节点。比如:
- 在 Web 方面可以直接利用浏览器提供的导航计时(NavigationTiming)和资源计时(ResourceTiming)接口来采集性能数据,非常方便。
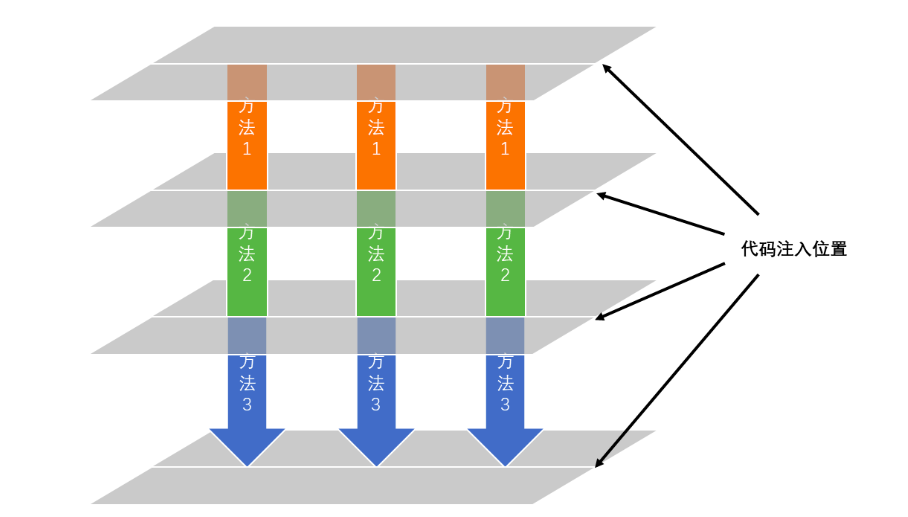
- 在 iOS、Android 这种 App 方面通过源代码插桩的方式进行。比如直接引入采集 SDK 然后硬编码在源代码中,或者通过 AOP 框架来进行动态代码注入。代码的注入位置就在每个方法的执行前和执行后(如下图所示)。
- 后端是分布式系统的主战场,有进程外和进程内两个维度的解决方案。
1)进程外的解决方案,例如运用 Zabbix 之类的无探针解决方案,调用系统或者服务自身提供的状态接口获取采集数据(如下图所示),以及对网络数据包的监听来获取网络性能方面的数据。
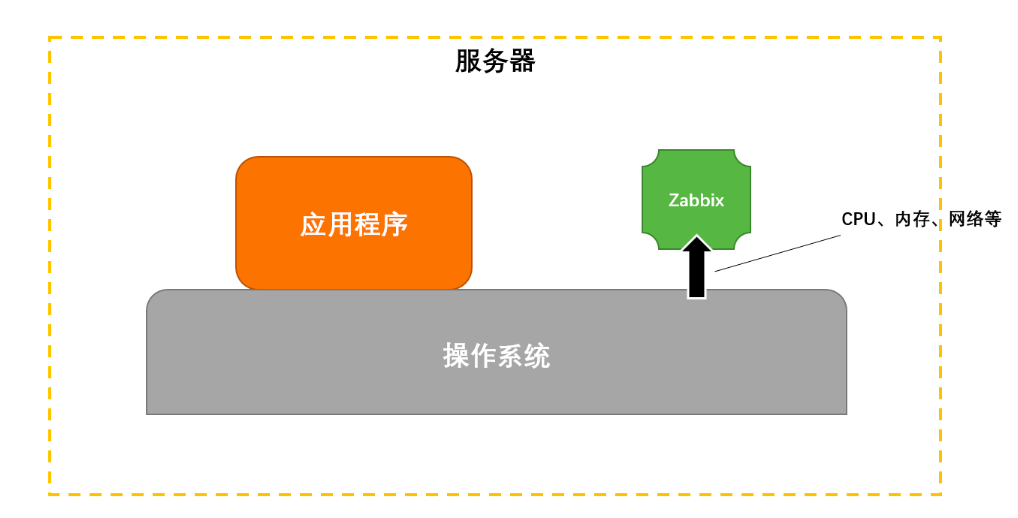
由于是进程外的,所以这类方案对我们的程序是无侵入的,最友好。但弊端也很明显,监控的粒度太粗,只能进行一些外在的监控。比如可以发现 CPU 突然飙高了,但是并不知道可疑的接口是哪个,更无法知道是哪行代码导致的问题。因此,只适合作为辅助方案。
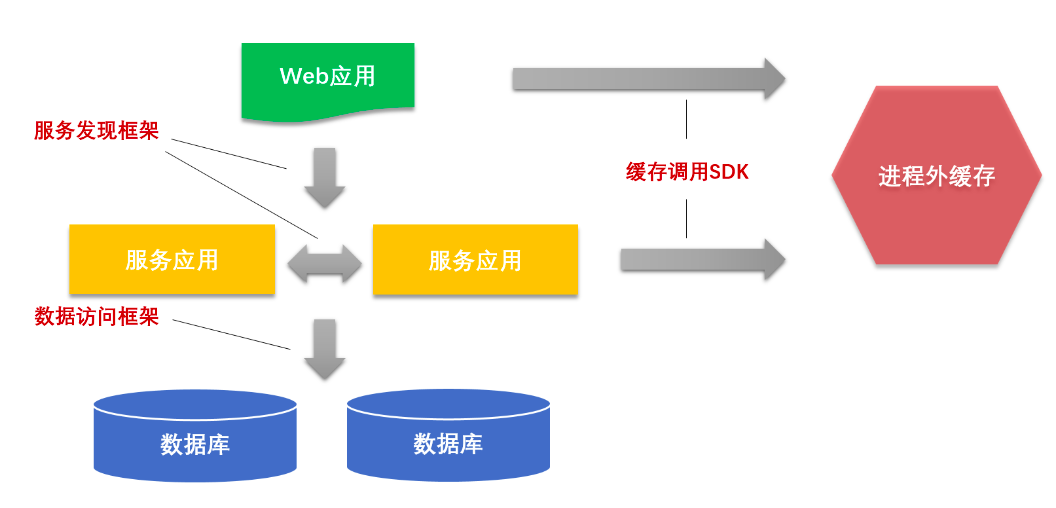
2)后端的进程内解决方案可以解决进程外方案的短板,但是由于需要侵入到应用程序内部,所以对性能和稳定性会带来一定的影响。关于这类方案我们有很多的选择可以来实现它:可以同 APP 一样运用采集 SDK 和 AOP 框架,还可以通过利用整个系统中的“连接”部分来进行,比如一些中间件(数据层访问框架、服务调用框架等)。
做好了监控,就做好了故障发现一半的工作。另外一半是什么呢?就是故障注入测试(Fault Insertion Test)。我们需要通过技术手段来主动制造“故障”,以此来提前检验系统在各种故障场景下的表现情况是否符合我们预期。
监控是一双眼睛,替你盯着故障,但是我们不能守株待兔,否则大部分突发的故障都会在生产环境发生。一旦发生就会对经营的业务产生或多或少的影响,甚至看似平静的系统下,藏着几个随时会引爆的炸弹,我们也不得而知。所以我们需要主动出击,主动去制造“故障”来锻炼系统。
在实际运用中,故障可以被注入到软件,也可以被注入到硬件。注入到软件的方式,无外乎这两种:
- 架设在软件与操作系统之间,当软件中的数据经过操作系统时,通过篡改数据完成注入。
- 通过 AOP 之类的框架进行代码注入来制造故障。
如果注入到硬件中就简单很多,直接运行一段代码把 CPU、网卡等吃满即可。
故障注入测试的过程大致是这样,在故障模型库中选择一个模型,然后将该模型对应的故障注入到一个在独立的环境中运行并且被包裹了一层“炸药包”的系统,相当于在你指定的地方去“点火”,随后进行监测并分析结果(如下图所示)。
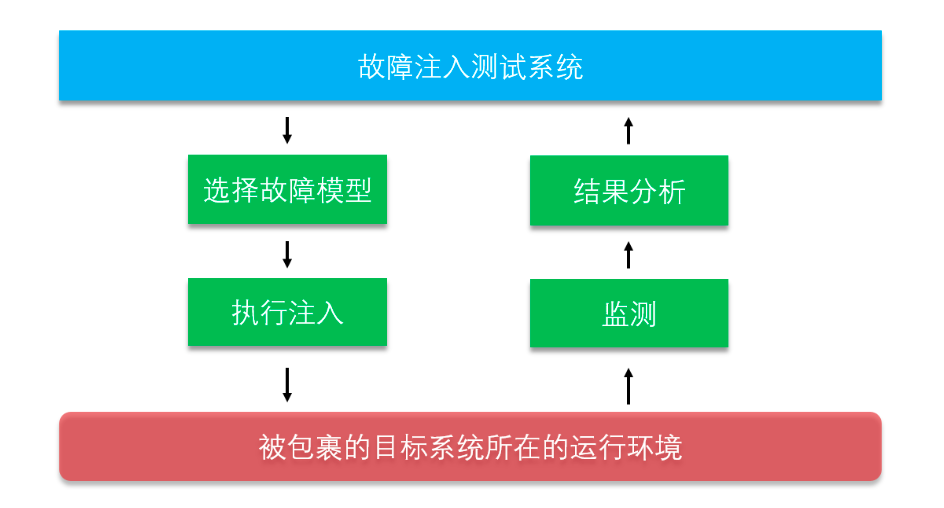
故障消除
现在已经能够很容易的发现故障了,我们就可以通过综合运用隔离性、横向扩展、代理、负载均衡、熔断、限流、降级等等机制来快速的“掐灭故障”。
分布式系统的规模越大,耦合越严重,各个子系统之间通过网络连接在一起,就如赤壁之战中的曹军连在一起的船舶一样,只要其中一个着火了就会就近蔓延。所以,一旦发现某个子系统挂了,就需要尽快切断与它的联系,保证自己能够不受连累,防止雪崩的发生。
我们可以首先运用 docker 之类的技术将每个应用在运行时的环境层面隔离开来。然后,通过横向扩展让每个应用允许被“Copy”,以此来部署多个副本。接着,结合代理和负载均衡让这些副本可以共同对外提供服务,使得每个应用程序本身先具备“高可用”。最后的三大防御措施,熔断、限流、降级来快速“掐灭故障”,避免故障在不同的应用程序间扩散。
故障善后
“故障消除”避免了级联故障导致的系统性风险,这时整个分布式系统已经具备健壮性了。但是对正在使用系统的用户来说,这些故障还是可见的,因为会反映成他实际操作中的错误提示,甚至导致流程无法继续。这对我们“衣食父母”来说并不友好,最终可能会导致用户的流失。
所以,我们应该通过一些补偿和缓冲的方式将故障产生的影响降到最低,尽可能的去包容故障,让用户无感。并且,这些善后工作应该与“故障发现”、“故障消除”一起形成一个完整的体系,以及尽可能的自动化。
前面我们聊到,故障产生的原因要么是调用的节点处于异常状态,要么是通信链路异常。所以,要做好“故障善后”,就需要在节点之间的连接上做文章。根据 CAP 定理、BASE 理论,我们已经很清楚两个进程之间的调用方式。一是直接点对点的同步调用,或者是通过一些技术中间层进行异步的调用。
那么,针对同步调用我们可以有两种方式去实施。
- 首先是立即重试。很多时候,相同节点的所有副本可能只是由于网络原因,导致其中的某个节点无法被访问。那么,此时如果后端的负载均衡策略只要不是 Hash 类的策略,并且后端服务的方法是无状态的且支持幂等性的,就可以立马重试一次,大概率就能调用成功。不过,这个方案潜在的一个副作用是,如果后端服务总体负载很高,且无法自动弹性扩容,那么会进一步加剧一些压力。所以,你可以增加一个允许被重试的条件,以及为实际的重试操作增加一个约定。比如,这两个耗时分别都不能大于 1 秒。
- 方式二,将可以容忍最终一致性的同步调用产生的出错消息进行异步重发。比如,电商网站中提交订单中所依赖的订单模块产生故障,我们可以将其暂存到消息队列中,然后再进行异步的投递,同时提示给用户“订单正在加紧创建中,稍后通知您支付”之类的语句,至少先让订单能够下进来。这本质上算得是一个“降级”方案。
如果本身就是一个异步调用,比如最常见的就是发往消息队列出现异常。因为,一个高可用的消息队列集群,大多数情况下导致消息无法被投递的原因是网络问题。这个时候,理论上我们可以基于每个应用的本地磁盘部署一个本地 MQ,可以避免很大一部分这个问题。但是实际往往不会这么做,因为这么做的性价比太低,原因有两点:
- 这么多消息队列维护成本太高。
- 如果用到的是消息队列集群,本身已具备软件层面的高可用,所以出现这个问题的概率很低。
所以,这个时候我们大多会通过定时的任务(job)去进行对账(数据一致性检测)。任务(job)的具体实现上尽可能做到自动修正,否则通知人工介入。
总结
这次,我们系统化的梳理了如何来应对“故障”,以此来达到做好高可用的目的。核心观点就是:保持着怀疑的心态,去发现故障、消除故障、并且为故障做善后。
至此,我们有必要开始衡量我们的高可用到底做的怎么样了。就是统计一下全年的故障时间,得出所谓的“几个 9”的结论。
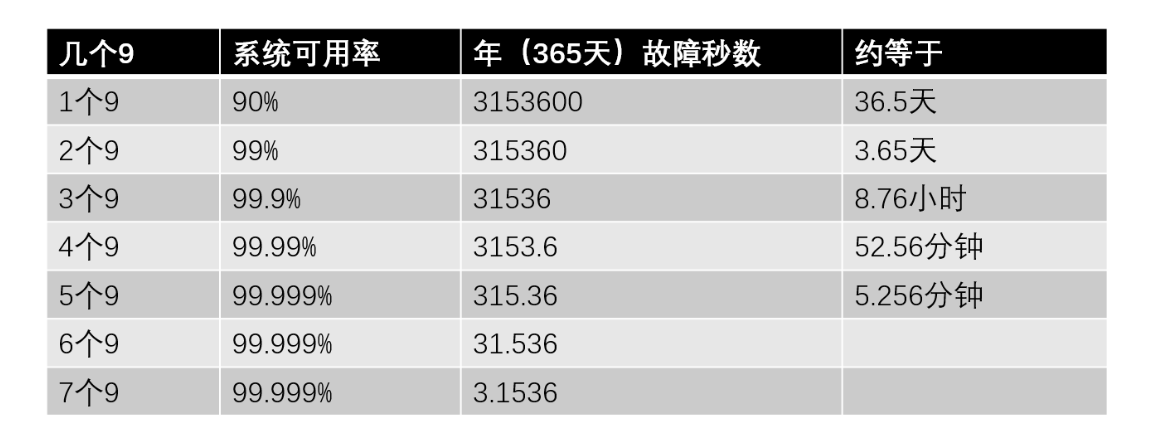
但是,到目前为止,我们在通往几个 9 的道路上只走了一半。剩下的一半就是讨论如何做到无限接近于 100% 的高可用。
你在工作中,还通过哪些方式为高可用作出过努力呢?主流和非主流都可以说下,一起开开脑洞。 欢迎在下方评论区留言。
延伸阅读:分布式系统系列文章
第一篇:《拨云见日看什么是分布式系统?》
第二篇:《详解分布式系统本质:“分治”和“冗余”》
第三篇:《别忽视分布式系统这六大“暗流”》
第四篇:《跨进程通信,到底用长连接还是短连接》
第五篇:《数据库如何确保其操作被 100% 正确执行?》
转自 https://www.infoq.cn/article/XUo5wq-d5VC6TAs4vU7o