 Linuxeden开源社区
Linuxeden开源社区谷歌开源了一个分布式机器学习库 GPipe,这是一个用于高效训练大规模神经网络模型的库。
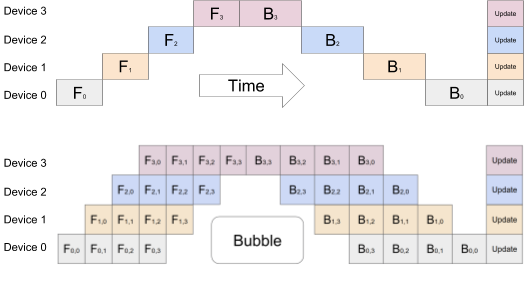
GPipe 使用同步随机梯度下降和管道并行进行训练,适用于由多个连续层组成的任何 DNN。重要的是,GPipe 允许研究人员轻松部署更多加速器来训练更大的模型,并在不调整超参数的情况下扩展性能。
开发团队在 Google Cloud TPUv2s 上训练了 AmoebaNet-B,其具有 5.57 亿个模型参数和 480 x 480 的输入图像尺寸。该模型在多个流行数据集上表现良好,包括将 single-crop ImageNet 精度推至 84.3%,将 CIFAR-10 精度推至 99%,将 CIFAR-100 精度推至 91.3%。
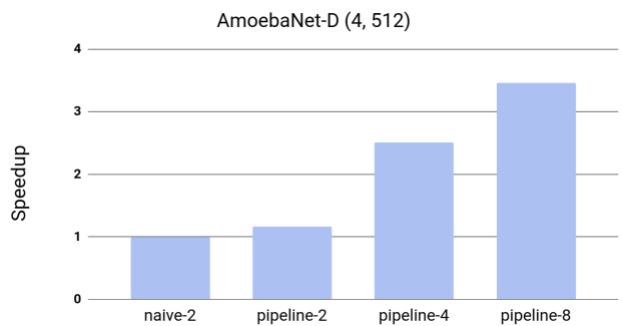
GPipe 可以最大化模型参数的内存分配。团队在 Google Cloud TPUv2上进行了实验,每个 TPUv2 都有 8 个加速器核心和 64 GB 内存(每个加速器 8 GB)。如果没有 GPipe,由于内存限制,单个加速器可以训练 8200 万个模型参数。由于在反向传播和批量分割中重新计算,GPipe 将中间激活内存从 6.26 GB 减少到 3.46GB,在单个加速器上实现了 3.18 亿个参数。此外,通过管道并行,最大模型大小与预期分区数成正比。通过 GPipe,AmoebaNet 能够在 TPUv2 的 8 个加速器上加入 18 亿个参数,比没有 GPipe 的情况下多 25 倍。
核心 GPipe 库目前开源在 Lingvo 框架下。
具体原理可以查看谷歌的发布公告。
转自 https://www.oschina.net/news/104946/google-opensource-gpipe