 Linuxeden开源社区
Linuxeden开源社区作者 ,译者 CarolGuo
本文最初发布于GitHub,经原作者授权由InfoQ中文站翻译并分享。
该指南能帮助同行研究者和爱好者们轻松地使用Kubernetex GPU集群来自动化和加速他们的深度学习训练。因此,我将解释如何轻松地在多个Ubuntu 16.04裸机服务器上搭建一个GPU集群,并提供一些有用的脚本和.yaml文件来完成这些工作。
另外,如果你需要把Kubernetes GPU集群用于其他地方,该指南可能对你也有帮助。
为什么写这个指南?
我一直在创业公司understand.ai实习,在那里我留意到了一个麻烦:首先得在本地设计一个机器学习算法,然后将其放到云上用不同的参数和数据集来训练模型。这第二步,将算法放到云上进行全面的训练,所耗费的时间要比想象的更长,通常让人很沮丧而且涉及到很多陷阱。
因此,我决定解决这个问题,让第二步变得容易、简单和快捷。
我写了这篇很有用的指南,描述了每个人如何设置他们自己的Kubernetes GPU集群来加速他们的工作。
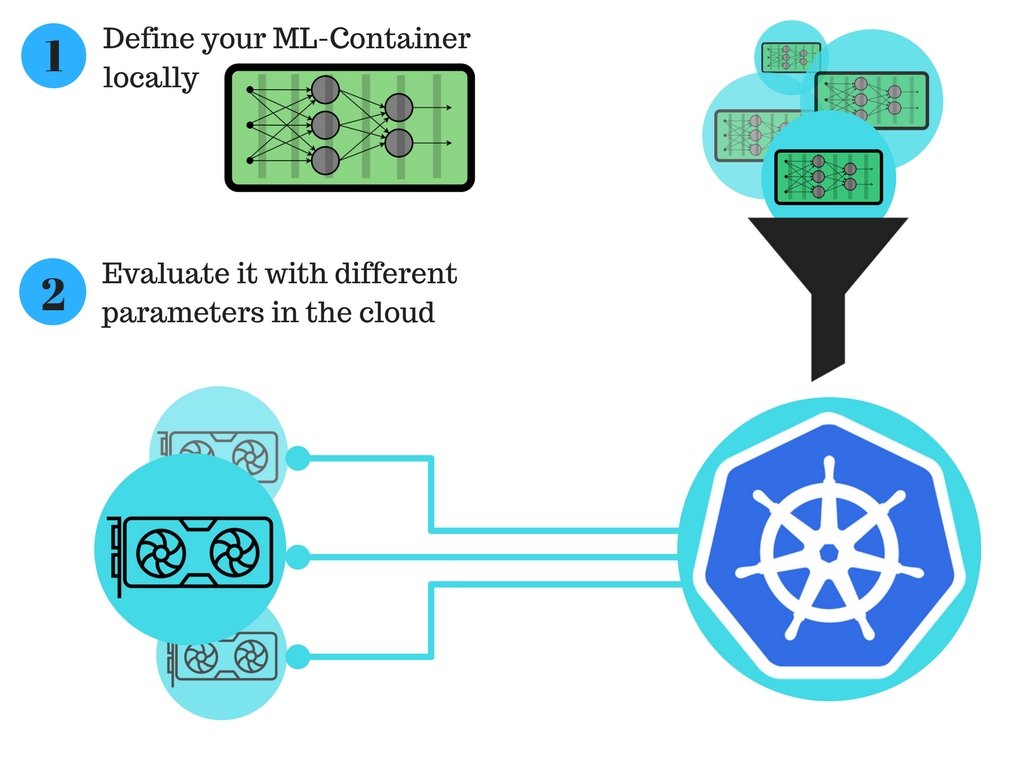
给深度学习研究者的新处理过程:
用Kubernetes GPU集群进行自动化的深度学习训练,它能极大地改进在云上训练模型的过程。
(点击放大图像)
声明
下面的章节可能有些武断。Kubernetes是一个进化的、快节奏的环境,这就意味着这个指南很可能会在某个时间过时,这取决于作者的空余时间和个人贡献。因此,非常感谢对此的贡献。
Kubernetes快速参考
如果你需要重温下Kubernetes知识,下面这些文章很有用。
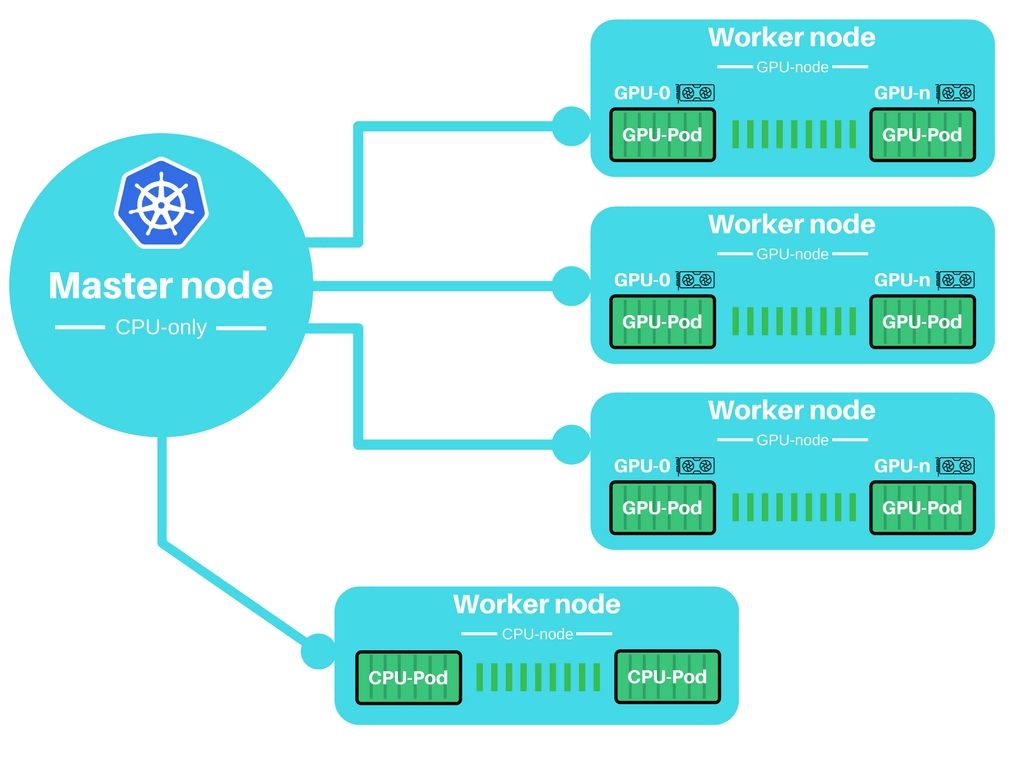
集群结构粗览
核心想法是用一个很小的只有CPU的master节点来控制一组GPU worker节点。
(点击放大图像)
初始化节点
在我们使用集群之前,要先对其初始化,这一点很重要。因此,要手动地初始化每个节点,随后将它加入集群中。
我的设置
该配置非常适合这里所描述的用例。对其他用例、操作系统等,需要进一步地调整配置。
Master
- Ubuntu 16.04带root权限
- 我用了一个Google Compute Engine VM实例
- SSH权限
- 停用ufw
- 可用端口(udp和tcp)
- 6443,443,8080
- 30000-32767(仅在需要时激活)
- 这些将被用于获取集群外部的服务
Worker
- Ubuntu 16.04带root权限
- 我用了一个Google Compute Engine VM实例
- SSH权限
- 停用ufw
- 可用端口(udp和tcp)
- 6443,443
关于安全:当然,如果你想在产品中使用,就应该启用某些防火墙;这里出于简单考虑我停用了ufw。设置Kubernetes以用于实际的产品中,理所当然应该启用某些防火墙如ufw、iptables或者你的云提供商的防火墙。在云上设置集群会更加复杂。通常云提供商的防火墙与主机级别的防火墙是分开的。你可能需要停用ufw、并开启云提供商防火墙的规则来让这篇文档里的步骤生效。
设置指南
这些指南涵盖了我在Ubuntu 16.04的经验,对其他操作系统可能适用,也可能不适用。
我创建了两个脚本对master和worker节点完全初始化。脚本如下所示。如果你想用快速通道,可以直接使用这些脚本。否则,我建议你阅读一步一步的指南。
快速通道设置脚本
MASTER节点
运行初始化脚本,记下token。
Token的格式类似于–token f38242.e7f3XXXXXXXXe231e。
chmod +x init-master.sh sudo ./init-master.sh <IP-of-master>
WORKER节点
运行初始化脚本,使用正确的token和master IP。
端口通常是6443。
chmod +x init-worker.sh sudo ./init-worker.sh <Token-of-Master> <IP-of-master>:<Port>
详细的一步一步指南
MASTER节点
1.将Kubernetes Repository加入packagemanager
sudo bash -c 'apt-get update && apt-get install -y apt-transport-https curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb http://apt.kubernetes.io/ kubernetes-xenial main EOF apt-get update'
2.安装docker-engine、kubeadm、kubectl和kubernetes-cni
sudo apt-get install -y docker-engine sudo apt-get install -y kubelet kubeadm kubectl kubernetes-cni sudo groupadd docker sudo usermod -aG docker $USER echo 'You might need to reboot / relogin to make docker work correctly'
3.由于我们想创建一个使用GPU的集群,我们要在master节点上启用GPU加速功能。记住,在Kubernetes之后的版本中,这一步可能被淘汰了或者完全更改了。
3.I 在集群初始化之前,添加GPU支持到Kubeadm配置。
这一步必须对集群中的每一个节点进行,即使某些节点没有GPU。
sudo vim /etc/systemd/system/kubelet.service.d/<<Number>>-kubeadm.conf
因此,在ExecStart后追加上标签–feature-gates=”Accelerators=true”,最终格式如下:
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS [...] --feature-gates="Accelerators=true"
3.II 重启kubelet
sudo systemctl daemon-reload sudo systemctl restart kubelet
4.现在初始化master节点。
你需要master节点的IP。而且,这一步会向你提供认证信息,用于添加worker节点,因为要记住你的token。
Token的格式类似于–token f38242.e7f3XXXXXXXXe231e 130.211.XXX.XXX:6443。
sudo kubeadm init --apiserver-advertise-address=<ip-address>
5.由于Kubernetes 1.6从ABAC卷管理变成了RBAC式,因此我们需要向用户公布认证信息。每一次登录机器,都需要执行这一步。
sudo cp /etc/kubernetes/admin.conf $HOME/ sudo chown $(id -u):$(id -g) $HOME/admin.conf export KUBECONFIG=$HOME/admin.conf
6.安装网络插件让节点能相互通信。Kubernetes 1.6对网络插件有一些要求,如:
- 基于CNI的网络
- RBAC支持
这篇GoogleSheet文档包含很多合适的网络插件。链接: GoogleSheet Network Add-on comparison。
出于个人的偏好,我会使用wave-works。
kubectl apply -f https://git.io/weave-kube-1.6
7.现在都设置好了。检查所有的pod都在线上,确认一切运转顺利。
kubectl get pods --all-namespaces
N. 如果你想撤掉master节点,你需要重置它。
sudo kubeadm reset
WORKER NODE
前面几步对你而言应该很熟悉了,能让进程加快一些。
1.将Kubernetes Repository加入packagemanager
sudo bash -c 'apt-get update && apt-get install -y apt-transport-https curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb http://apt.kubernetes.io/ kubernetes-xenial main EOF apt-get update'
2.安装docker-engine、kubeadm、kubectl和kubernetes-cni
sudo apt-get install -y docker-engine sudo apt-get install -y kubelet kubeadm kubectl kubernetes-cni sudo groupadd docker sudo usermod -aG docker $USER echo 'You might need to reboot / relogin to make docker work correctly'
3.由于我们想创建一个使用GPU的集群,我们要在master节点上启用GPU加速功能。记住,在Kubernetes之后的版本中,这一步可能被淘汰了或者完全更改了。
3.I 在集群初始化之前,添加GPU支持到Kubeadm配置。
这一步必须对集群中的每一个节点进行,即使某些节点没有GPU。
sudo vim /etc/systemd/system/kubelet.service.d/<<Number>>-kubeadm.conf
因此,在ExecStart后追加上标签–feature-gates=”Accelerators=true”,最终格式如下:
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS [...] --feature-gates="Accelerators=true"
3.II 重启kubelet
sudo systemctl daemon-reload sudo systemctl restart kubelet
4.现在我们将worker加入到集群中。
你需要记住master节点的token,所以查看下节点。
sudo kubeadm join --token f38242.e7f3XXXXXXe231e 130.211.XXX.XXX:6443
5.完成。在master上检查节点,看看是否一切运转顺利。
kubectl get nodes
N. 如果你想撤掉worker节点,你需要将该节点从集群中移除,然后重置该节点。从集群中移除worker节点是很有帮助的。
在master节点上:
kubectl delete node <worker node name>
在worker节点上
sudo kubeadm reset
客户端
为了控制你的集群,如从客户端控制master,你需要对客户端的正确用户进行认证。该指南中并没有为客户端创建一个单独的用户,我们只是从master节点复制用户。相信我,这样做会更简单。
[会在将来加入如何添加用户的指导]
1.在客户端安装kubectl。我只在mac上测试过,但应该也适用linux。我不知道是否适用于windows,但又有谁关心windows呢。
Mac
brew install kubectl
Ubuntu 你要么遵循官方指南https://kubernetes.io/docs/tasks/tools/install-kubectl/,要么从上面的worker指南中提取需要的步骤(可能只在Ubuntu上可行)。
2.将master的admin认证拷贝到客户端。
scp uai@130.211.XXX.64:~/admin.conf ~/.kube/
3.将admin.conf配置和认证信息添加到Kubernetes配置中。你需要对每个代理都执行该步骤。
export KUBECONFIG=~/.kube/admin.conf
你可以在本地的客户端上使用kubectl了。
4.你可以测试列出所有的pod
kubectl get pods --all-namespaces
安装Kubernetes dashboard
Kubernetes dashboard非常的漂亮,它向那些跟我一样喜欢摆弄脚本的人提供了很多功能。要使用dashboard的话,你需要让客户端运行,RBAC会确保这一点。
你可以直接在master节点上或者从客户端运行下面的步骤。
1.检查已经安装了dashboard: kubectl get pods –all-namespaces | grep dashboard
2.如果没有安装,则安装它
kubectl create -f https://git.io/kube-dashboard
如果不成功,检查.yaml中定义的容器git.io/kube-dashboard是否存在。(这个软件故障曾让我花费了很多时间)
为了能访问你的dashboard,你需要在客户端进行认证。
3.添加dashboard代理到客户端。
在客户端运行:
kubectl proxy
4.用浏览器访问dashboard,访问127.0.0.1:8001/ui。
如何构建你的GPU容器
这里帮助你运行一个需要GPU权限的Docker容器。
在该指南中,我选择创建一个Docker容器的例子,它用TensorFlow GPU二进制文件,并能在Jupyter笔记本中运行TensorFlow程序。
请记住,该指南适用于Kubernetes 1.6,因此可能不适用于今后的变化。
.yml的关键部分
为了能够让你的带CUDA的Nvidia GPU运行,你需要将Nvidia驱动和CUDA库文件传给容器。因此,我们将使用hostPath,让Kubernetes pod能访问它们。实际的路径因机器而异,因为它们是由Nvidia驱动和CUDA安装程序来设置的。
volumes:
- hostPath:
path: /usr/lib/nvidia-375/bin
name: bin
- hostPath:
path: /usr/lib/nvidia-375
name: lib
将包含有驱动和CUDA的卷加载到容器中的正确目录下。根据你的容器的具体要求,这些设置可能有所不同。
volumeMounts:
- mountPath: /usr/local/nvidia/bin
name: bin
- mountPath: /usr/local/nvidia/lib
name: lib
因为你要告诉Kubernetes你需要n个GPU,所以你可以在这里定义这些需求。
resources:
limits:
alpha.kubernetes.io/nvidia-gpu: 1
这就是你需要创建Kuberntes 1.6容器的所有东西。
这是我的所有经验:
Kubernetes + Docker + Machine Learning + GPUs = 顶呱呱
GPU部署例子
文件example-gpu-deployment.yaml 描述了两部分,部署和服务,因为我想让juptyer笔记本能被外部访问。
运行kubectl来让其对外可见。
kubectl create -f deployment.yaml
文件deployment.yaml内容如下:
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: tf-jupyter
spec:
replicas: 1
template:
metadata:
labels:
app: tf-jupyter
spec:
volumes:
- hostPath:
path: /usr/lib/nvidia-375/bin
name: bin
- hostPath:
path: /usr/lib/nvidia-375
name: lib
containers:
- name: tensorflow
image: tensorflow/tensorflow:0.11.0rc0-gpu
ports:
- containerPort: 8888
resources:
limits:
alpha.kubernetes.io/nvidia-gpu: 1
volumeMounts:
- mountPath: /usr/local/nvidia/bin
name: bin
- mountPath: /usr/local/nvidia/lib
name: lib
---
apiVersion: v1
kind: Service
metadata:
name: tf-jupyter-service
labels:
app: tf-jupyter
spec:
selector:
app: tf-jupyter
ports:
- port: 8888
protocol: TCP
nodePort: 30061
type: LoadBalancer
---
为了验证这些设置是正确的,你可以访问JupyterNotebook实例,链接是http://<IP-of-master>:30061。
现在我们要验证你的JupyterNotebook实例可以访问GPU。因此,在一个新的笔记本中运行下面的程序。它将列出tensorflow可用的所有服务。
from tensorflow.python.client import device_lib
def get_available_devices():
local_device_protos = device_lib.list_local_devices()
return [x.name for x in local_device_protos]
print(get_available_devices())
输出结果应该类似于[u’/cpu:0′, u’/gpu:0′]。
一些有用的命令
Get命令,输出基本信息
kubectl get services # 列出该命名空间的所有服务 kubectl get pods --all-namespaces # 列出所有命名空间的所有pod kubectl get pods -o wide # 列出该命名空间的所有pod,给出细节 kubectl get deployments # 列出所有部署 kubectl get deployment my-dep # 列出给定部署
Describe命令,输出冗长的信息
kubectl describe nodes <node-name> kubectl describe pods <pod-name>
删除资源
kubectl delete -f ./pod.yaml # 删除pod,其类型和名字被定义在pod.yaml中 kubectl delete pod,service baz foo # 删除名字为“baz”和“foo”的pod和服务 kubectl delete pods,services -l name=<myLabel> # 删除标签名为myLabel的pod和服务 kubectl -n <namespace> delete po,svc --all # 删除命名空间my-ns的所有pod和服务
进入某个pod的bash控制台:
kubectl exec -it <pod-name> -- /bin/bash
致谢
有很多指南、github仓库、问题和帮助过我的人们。
我想感谢每一个人的帮助。
特别感谢创业公司understand.ai的支持。
作者
Frederic Tausch – 原创 – Langhalsdino
许可
该项目采用MIT许可,具体细节请查看LICENSE.md文件。
查看英文原文:How to automate deep learning training with Kubernetes GPU-cluster
转自 http://www.infoq.com/cn/articles/kubernetes-gpu-cluster-to-automate-deep-learning-training