 3G Eden
3G Eden RSS
RSS
�ڴ�ͳ������оƬ�г���Ӣ�ض��Ǹ����ްԣ�������IBM Power����ARM��Ӫ����ռ�еķݶ��������ս��ת�Ƶ��˹���������IBM�ƺ��������ơ�
����ý����������IBM��NVIDIA�����Ƴ����·�����IBM Power Systems S822LC for High Performance Computing�����������Ʒ�ֱ�ΪIBM Power Systems S821LC��IBM Power Systems S822LC for Big Data��������һ�����ֿɿ������Ⲣ����һ����ͨ�ķ�����������ר��Ϊ�˹����ܡ�����ѧϰ������Ӧ�ó������Ƴ��ġ�
IBM�ٷ����ƣ��������������ݴ����ٶȱ�����ƽ̨��5������Ӣ�ض�x86��������ȣ�ÿ��Ԫ��ƽ�����ܸ߳�80%��

����������Ӣ�ض�x86ǿ���ģ�
���˽⣬�ÿ������ʹ��������IBM Power8 CPU��4��NVIDIA Tesla P100 GPU��Power8��ĿǰIBM��ǿ��CPU����֮ǰý�������������������������Ҫ����Ӣ�ض�E7 v3�ģ���Tesla P100��NVIDIA����ŷ����ĸ����ܼ��㣨HPC���Կ�����������������ڴ�����������Ȼ������
ԭ����������
��һ�����CISCָ������õ�RISCָ���Power��������ͬʱִ�ж���ָ��ɽ�һ��ָ��ָ�ɶ�����̻��̣߳����ɶ��������ͬʱִ�У���˲��д�������Ҫ���ڻ���CISC�ܹ���Ӣ�ض�x86оƬ��
���⣬��������������֮��������Power8��Tesla P100֮���“���”��
Power�ܹ�����һ���ص���Ǿ��г�ַ���GPU���ܵ����ơ�
ʵ���ϣ�Tesla P100�������汾��һ����NVIDIA����4���Ƴ���NVLink�棬��һ����6�·�����PCI-E�汾����������ǰ���Ǻ��ߵļ�ǿ�棬��IBM Power8��Ե�����Tesla P100 NVLink�档
Tesla P100���õ���Pascal�ܹ����ܹ�ʵ��CPU��GPU֮���ҳ��Ǩ�ƣ�����ÿ��NVLink�滹������4��ÿ��40 GB NVIDIA NVLink�˿ڣ��ֲ�����GPU��Ⱥ��NVLink��OpenPOWER Foundation���еĸ��ٻ�������������Ч�����ߴ�40GB/S������PCIE�������棬���������оƬ���м����������֧����һ����CPU��ָ������Power8��������֮һ��Ӣ�ض����ڴ�֮�У���
�����ζ�ţ�Power8 CPU�ܹ���Tesla P100 GPU�Ը��ߵ��ٶ����ͨ�ţ���һ���Կ���IBM Power Systems S822LC for High Performance Computing�е�CPU��GPU֮��������ٶ�Զ������ͨ����PCIe�����Ͻ������ݵı��֡�
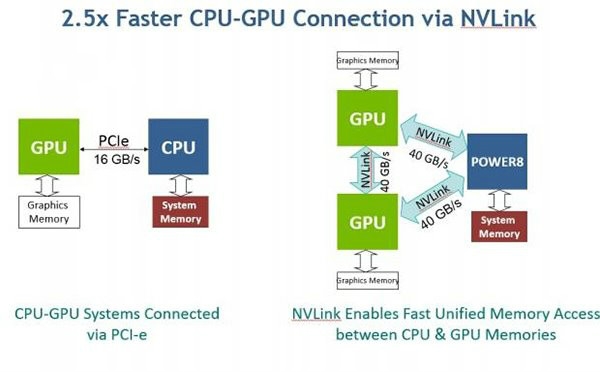
IBM��ʾ��“��һ������ζ�ţ���ͬ����GPU����PCI-E�����ϵ�x86ϵͳ�ϣ����ݿ�Ӧ�ó������ܷ���Ӧ�ó�������ܼ���Ӧ�ó��������ܹ���Ҫ��ö�����ݼ������С�”
���⣬Tesla P100�İ뾫�ȸ����������ܴﵽ��ÿ��21���ڴ� —— �Ȳ����ִ�PCI-E��۵�GPU�߳���Լ14%�������Ĵ���������ѵ���������������Ҫ�Բ��Զ�����
IBM�����˸�����Աȣ����Ͽ�Power S822LC��������Tesla K80 GPU��������ȣ��¿�������ļ������������������ࡣ
Ԥ������������IBM Power9��������CPU+GPU��ϵ��Ż���
Ϊ����“CPU+GPU”��
������֪�����˹������˹����ܺ����ѧϰ�ȼ��������ϣ�CPU���Ѳ������Ρ���ˣ�������ҵ���Ƴ��˹�����ר��оƬ�������ȸ��TPU��Tensor Processing Unit��������ҵ����ʿ��ͦFPGA���ʺ����ѧϰ���㷨����Ҳ��Ӣ�ض��Ը��չ�Altera����Ҫԭ��
�����������������CPU�ķ�������δ���죬Ŀǰ�������ҵ���õ���Ȼ��“CPU+GPU”����ϣ����߳�Ϊ�칹��������ͨ����˵���������칹ģʽ�£�Ӧ�ó���Ĵ��в�����CPU�����У���GPU��ΪЭ����������Ҫ������������صIJ��֡�
��Ϊ��CPU��ȣ�GPU�����Ʒdz����ԣ�
1.CPU��ҪΪ����ָ����Ż�����GPU����Ϊ���ģ�IJ���������Ż������ԣ������ڴ��ģ����������ٶȸ��죻
2.ͬ������£�GPU��ӵ�и�������㵥Ԫ������������ij˼ӵ�Ԫ���������㵥Ԫ�ȵȣ���
3.һ������£�GPUӵ�и�������� Memory������ڴ���������Ӧ����Ҳ���кܺõ����ܡ�
4.GPU����Դ������ԶԶ����CPU��
��Ȼ���Ⲣ�������˹����ܷ�������CPUû������CPU��Ȼ�Ǽ������ɻ�ȱ��һ���֣������ѧϰ�㷨���������л���Ҫ�����ܵ�CPU��ִ��ָ��Һ�GPU�������ݴ��䣬ͬʱ����CPU��ͨ���Ժ�GPU�ĸ������������������ܴﵽ��õ�Ч����ͨ��˵����ʵ��CPU��GPU��Эͬ���㡣
��ȻNVIDIA��Intel��оƬ������ΪGPU��CPU��ǿ���������˿�ˮս����ʵ������Щ��ҵ�Ѿ���ʼ���칹�����ϼӴ����з����ȣ������ڽ����ڣ�CPU��GPU�Ľ�Ͻ�������Ϊ�˹�������������Ч�ķ�����