 3G Eden
3G Eden RSS
RSSApache Calcite是面向Hadoop新的查询引擎,它提供了标准的SQL语言、多种查询优化和连接各种数据源的能力,除此之外,Calcite还提供了OLAP和流处理的查询引擎。正是有了这些诸多特性,Calcite项目在Hadoop中越来越引入注目,并被众多项目集成。
Calcite之前的名称叫做optiq,optiq起初在Hive项目中,为Hive提供基于成本模型的优化,即CBO(Cost Based Optimizatio)。2014年5月optiq独立出来,成为Apache社区的孵化项目,2014年9月正式更名为Calcite。Calcite项目的创建者是Julian Hyde,他在数据平台上有非常多的工作经历,曾经是Oracle、 Broadbase公司SQL引擎的主要开发者、SQLStream公司的创始人和主架构师、Pentaho BI套件中OLAP部分的架构师和主要开发者。现在他在Hortonworks公司负责Calcite项目,其工作经历对Calcite项目有很大的帮助。除了Hortonworks,该项目的代码提交者还有MapR、Salesforce等公司,并且还在不断壮大。
Calcite的目标是“one size fits all(一种方案适应所有需求场景)”,希望能为不同计算平台和数据源提供统一的查询引擎,并以类似传统数据库的访问方式(SQL和高级查询优化)来访问Hadoop上的数据。
Apache Calcite具有以下几个技术特性:
- 支持标准SQL语言;
- 独立于编程语言和数据源,可以支持不同的前端和后端;
- 支持关系代数、可定制的逻辑规划规则和基于成本模型优化的查询引擎;
- 支持物化视图(materialized view)的管理(创建、丢弃、持久化和自动识别);
- 基于物化视图的Lattice和Tile机制,以应用于OLAP分析;
- 支持对流数据的查询。
下面对其中的一些特性更详细的介绍。
基于关系代数的查询引擎
我们知道,关系代数是关系型数据库操作的理论基础,关系代数支持并、差、笛卡尔积、投影和选择等基本运算。关系代数是Calcite的核心,任何一个查询都可以表示成由关系运算符组成的树。 你可以将SQL转换成关系代数,或者通过Calcite提供的API直接创建它。比如下面这段SQL查询:
SELECT deptno, count(*) AS c, sum(sal) AS s
FROM emp
GROUP BY deptno
HAVING count(*) > 10
可以表达成如下的关系表达式语法树:
LogicalFilter(condition=[>($1, 10)])
LogicalAggregate(group=[{7}], C=[COUNT()], S=[SUM($5)])
LogicalTableScan(table=[[scott, EMP]])
当上层编程语言,如SQL转换为关系表达式后,就会被送到Calcite的逻辑规划器进行规则匹配。在这个过程中,Calcite查询引擎会循环使用规划规则对关系表达式语法树的节点和子图进行优化。这种优化过程会以一个成本模型作为参考,每次优化都在保证语义的情况下利用规则来降低成本,成本主要以查询时间最快、资源消耗最少这些维度去度量。
使用逻辑规划规则等同于数学恒等式变换,比如将一个过滤器推到内连接(inner join)输入的内部执行,当然使用这个规则的前提是过滤器不会引用内连接输入之外的数据列。图1就是一个将Filter操作下推到Join下面的示例,这样做的好处是减少Join操作记录的数量。
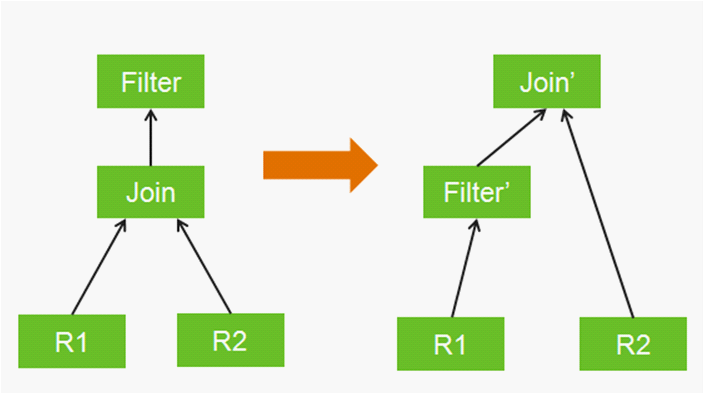
图1:一个逻辑规划的规则匹配(Filter操作下沉)
非常好的一点是Calcite中的查询引擎是可以定制和扩展的,你可以自定义关系运算符、规划规则、成本模型和相关的统计,从而应用到不同需求的场景。
动态的数据管理系统
Calcite的设计目标是成为动态的数据管理系统,所以在具有很多特性的同时,它也舍弃了一些功能,比如数据存储、处理数据的算法和元数据仓库。由于舍弃了这些功能,Calcite可以在应用和数据存储、数据处理引擎之间很好地扮演中介的角色。用Calcite创建数据库非常灵活,你只需要动态地添加数据即可。
同时,前面提到过,Calcite使用了基于关系代数的查询引擎,聚焦在关系代数的语法分析和查询逻辑的规划制定上。它不受上层编程语言的限制,前端可以使用SQL、Pig、Cascading或者Scalding,只要通过Calcite提供的API将它们转化成关系代数的抽象语法树即可。
同时,Calcite也不涉及物理规划层,它通过扩展适配器来连接多种后端的数据源和处理引擎,如Spark、Splunk、HBase、Cassandra或者MangoDB。简单的说,这种架构就是“一种查询引擎,连接多种前端和后端”。
物化视图的应用
Calcite的物化视图是从传统的关系型数据库系统(Oracle/DB2/Teradata/SQL server)借鉴而来,传统概念上,一个物化视图包含一个SQL查询和这个查询所生成的数据表。
下面是在Hive中创建物化视图的一个例子,它按部门、性别统计出相应的员工数量和工资总额:
CREATE MATERIALIZED VIEW emp_summary AS
SELECT deptno, gender, COUNT(*) AS c, SUM(salary) AS s
FROM emp
GROUP BY deptno, gender;
;
因为物化视图本质上也是一个数据表,所以你可以直接查询它,比如下面这个例子查询男员工人数大于20的部门:
SELECT deptno FROM emp_summary
WHERE gender = ‘M’ AND c > 20;
更重要的是,你还可以通过物化视图的查询取代对相关数据表的查询,可参见图2。由于物化视图一般存储在内存中,且其数据更接近于最终结果,所以查询速度会大大加快。
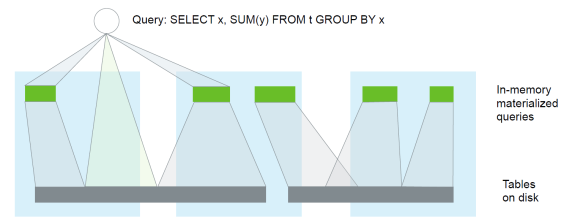
图2:查询、物化视图和表的关系
比如下面这个对员工表(emp)的查询(女性的平均工资):
SELECT deptno, AVG(salary) AS average_sal
FROM emp WHERE gender = 'F'
GROUP BY deptno;
可以被Calcite规划器改写成对物化视图(emp_summary)的查询:
SELECT deptno, s / c AS average_sal
FROM emp_summary WHERE gender = 'F'
GROUP BY deptno;
我们可以看到,多数值的平均运算,即先累加再除法转化成了单个除法。
为了让物化视图可以被所有编程语言访问,需要将其转化为与语言无关的关系代数并将其元数据保存在Hive的HCatalog中。HCatalog可以独立于Hive,被其它查询引擎使用,它负责Hadoop元数据和表的管理。
物化视图可以进一步扩展为DIMMQ(Discardable, In-Memory, Materialized Query)。简单地说,DIMMQ就是内存中可丢弃的物化视图,它是高级别的缓存。相对原始数据,它离查询结果更近,所占空间更小,并可以被多个应用共享,并且应用不必感知物化视图存在,查询引擎会自动匹配它。物化视图可以和异构存储结合起来,即它可以存储在Disk、SSD或者内存中,并根据数据的热度进行动态调整。
除了上面例子中的归纳表(员工工资、员工数量),物化视图还可以应用在其它地方,比如b-tree索引(使用基础的排序投影运算)、分区表和远端快照。总之,通过使用物化视图,应用程序可以设计自己的派生数据结构,并使其被系统自动识别和使用。
在线分析处理(OLAP)
为了加速在线分析处理,除了物化视图,Calcite还引入Lattice(格子)和Tile(瓷片)的概念。Lattice可以看做是在星模式(star schema)数据模型下对物化视图的推荐、创建和识别的机制。这种推荐可以根据查询的频次统计,也可以基于某些分析维度的重要等级。Tile则是Lattice中的一个逻辑的物化视图,它可以通过三种方法来实体化:1)在lattice中声明;2)通过推荐算法实现;3)在响应查询时创建。
下图是Lattice和Tile的一个图例,这个OLAP分析涉及五个维度的数据:邮政编码、州、性别、年和月。每个椭圆代表一个Tile,黑色椭圆是实体化后物化视图,椭圆中的数字代表该物化视图对应的记录数。
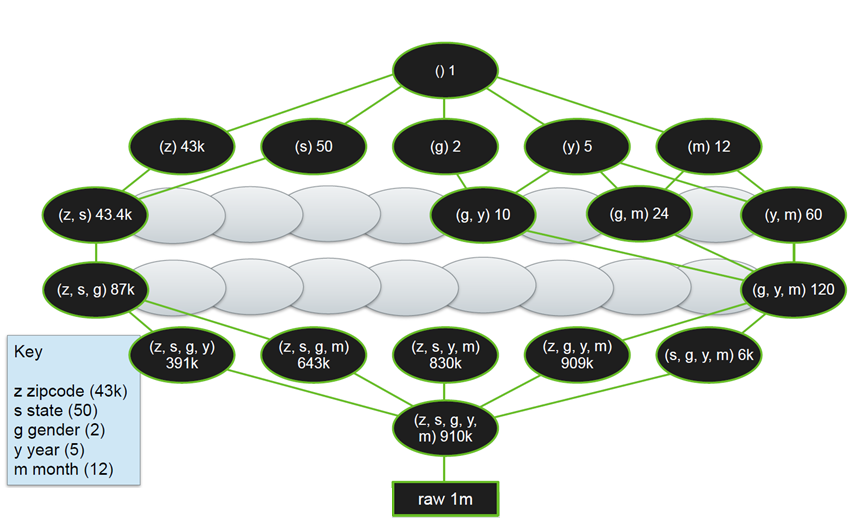
图3:Lattice和Tile的示例图
由于Calcite可以很好地支持物化视图和星模式这些OLAP分析的关键特性,所以Apache基金会的Kylin项目(Hadoop上OLAP系统)在选用查询引擎时就直接集成了Calcite。
支持流查询
Calcite对其SQL和关系代数进行了扩展以支持流查询。Calcite的SQL语言是标准SQL的扩展,而不是类SQL(SQL-like),这个差别非常重要,因为:
- 如果你懂标准SQL,那么流的SQL也会非常容易学;
- 因为在流和表上使用相同的机制,语义会很清楚;
- 你可以写同时对流和表结合的查询语句;
- 很多工具可以直接生成标准的SQL。
Calcite的流查询除了支持排序、聚合、过滤等常用操作和子查询外,也支持各种窗口操作,比如翻滚窗口(Tumbling window)、跳跃窗口(Hopping window)、滑动窗口(Sliding windows)、级联窗口(Cascading window)。其中级联窗口可以看作是滑动窗口和翻滚窗口的结合。
总结
Calcite是一种动态数据管理系统,它具有标准SQL、连接不同前端和后端、可定制的逻辑规划器、物化视图、多维数据分析和流查询等诸多能力,使其成为大数据领域中非常有吸引力的查询引擎,目前它已经或被规划集成到Hadoop的诸多项目中,比如Lingual (Cascading项目的SQL接口)、Apache Drill、Apache Hive、Apache Kylin、Apache Phoenix、Apache Samza和Apache Flink。