 3G Eden
3G Eden RSS
RSSYupoo!���������� ��Ŀǰ��������ͼƬ�����ṩ�̣�������վ�����ڴ����Ŀ�Դ����֮�ϡ�����Ϊ��ʹ�õ��Ŀ�Դ������Ϣ��
- ����ϵͳ��CentOS��MacOSX��Ubuntu
- ��������Apache��Nginx��Squid
- ���ݿ⣺MySQLmochiweb��MySQLdb
- ��������أ�Cacti��Nagios��
- �������ԣ�PHP��Python��Erlang��Java��Lua
- �ֲ�ʽ���㣺Hadoop��Mogilefs��
- ��־������AWStats
- ���������Redmine
- ��Ϣϵͳ��RabbitMQ��php-amqp
- ǰ�˿�ܣ�Mootools
- ����ϵͳ��Memcached��php-memcached��libmemcached��pylibmc��XCache��RedisRiak��Predis
- ͼƬ������GraphicsMagick��gmagick
- FTP���ߣ�vsftpd
- �������ߣ�VIM��Readline
- ���Թ��ߣ�Firebug��Xdebug
- �汾���ƣ�Mercurial
- ��������Solr
- �ʼ�����Postfix
- �����̣�Twisted��cURL��libevent��Net-SNMP��NTP
- �����Բ��ԣ�ibrowse
- ��Ⱥϵͳ��Heartbeat
- �������gevent
- ���ؾ��⣺IPVS
- Python��ܣ�bottle
- ����ͨ����OpenVPN
����Ϣ��Դ��http://www.yupoo.com/info/about/����
һ��Yupoo������ܹ�
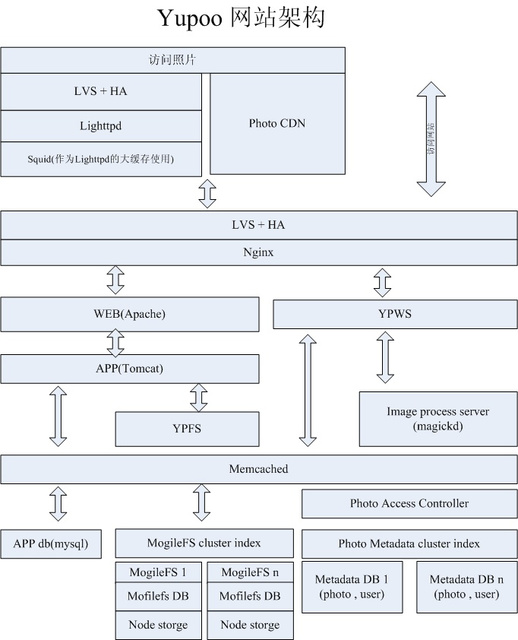
�����������Ե�ѡ��
Yupoo�ķ������˿���������Ҫ��PHP��Python������PHP���ڱ�дWeb����ͨ��HTTP���û�ֱ�Ӵ����� ��Python����Ҫ���ڿ����ڲ�����ͺ�̨�����ڿͻ�����ʹ���˴�������MooTools��ܵ�Javascript�� ���⣬Yupoo��ͼƬ�������̴�PHP����������������һ����������������nginx����Ϊnginx��һ��ģ�鿪��REST API��

������������ѡ��
ѡ��Squid��ԭ���ǡ�Ŀǰ��ʱ��û�ҵ�Ч�ʱ� Squid �ߵĻ���ϵͳ��ԭ�������ʵ�ȷ�ܲ������ Squid ǰ��װ�˲� Lighttpd, ���� url �� hash, ͬһ��ͼƬʼ�ջᵽͬһ̨ squid ȥ�����������ʳ�������ˡ���
ͬʱYupooҲʹ��Python������YPWS/YPFS��
- YPWS�CYupoo Web Server ���� Python������һ��С�� Web ���������ṩ������ Web �����⣬������������û���ͼƬ��������վ��ʾ�����жϣ�����װ���κ��п�����Դ�ķ������У���������ƿ��ʱ���������չ��
- YPFS�CYupoo File System �� YPWS ���ƣ�Ҳ�ǻ������ Web �������Ͽ�����ͼƬ�ϴ���������
�������������� Python ��Ч�ʣ�Yupoo �ϴ���ƽ���� del.icio.us ��д�� ��YPWS��Python�Լ�д�ģ�ÿ̨����ÿ����Դ���294������, ����ѹ����������10�����¡�
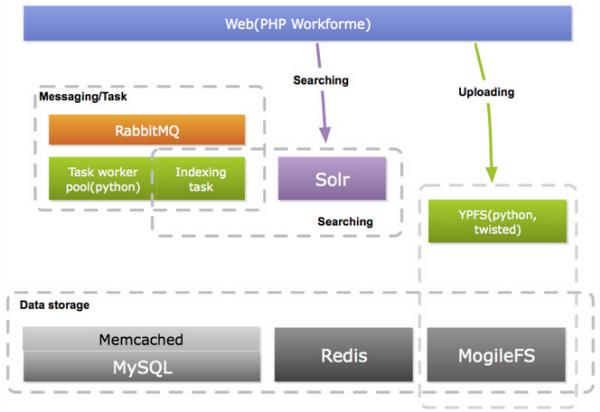
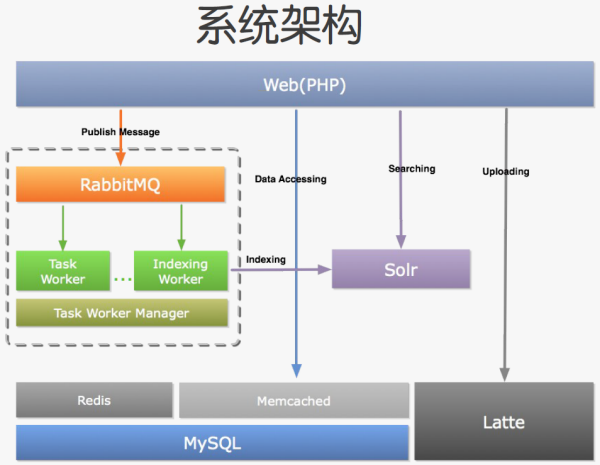
�ġ�Yupoo����Ϣϵͳ
����PHP�ĵ��߳�ģ�ͣ�Yupoo�Ѻ�ʱ�Ͼõ������I/O������HTTP���������з�������� ������Pythonʵ�ֵ������������ɣ��Ա�֤������Ӧ�ٶȡ���Щ������Ҫ�������ʼ����͡��������������ݾۺϺͺ��Ѷ�̬���͵ȵȡ�PHPͨ����Ϣ���� ��Yupoo�õ���RabbitMQ������������ִ�С���Щ�������Ҫ�ص�Ϊ��
- ���û����߶�ʱ������
- ��ʱ�Ƚϳ���
- ��Ҫ�첽ִ�е�
��������ϵͳ��Ҫ��Ϊ����Ϣ�ַ������̹�������������ɡ�
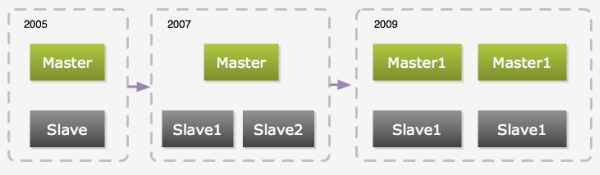
�塢���ݿ�����
���ݿ�һ������վ�ܹ��������ս�Եģ�ƿ��ͨ���������������������Ƭ�������ܴ����ݿ�Ҳ���ȳ������ص�ѹ�����⡣�ͺܶ�ʹ��MySQL�� 2.0վ��һ������������MySQL��Ⱥ�����˴������һ������һ���ӿ⡢��һ���������ӿ⡢ Ȼ����������ӿ��һ����չ���̡�
�������һ̨�����һ̨�ӿ���ɣ���ʱ�ӿ�ֻ�������ݺ����֣���������ֹ���ʱ���ӿ���ֶ�������⣬һ������£��ӿ� ������д������ͬ�����⣩������ѹ�������ӣ�������memcached����ʱֻ���仺�浥�����ݡ� ���ǣ��������ݵĻ��沢���ܺܺõؽ��ѹ�����⣬��Ϊ�������ݵIJ�ѯͨ���ܿ졣����һЩʵʱ��Ҫ�ߵ�Query�ŵ��ӿ�ȥִ�С�������ͨ�����Ӷ�� �ӿ���������ѯѹ�����������������������ӣ������дѹ��ҲԽ��Խ���ڲο���һЩ��ز�Ʒ��������վ���������������ݿ��֡�Ҳ���ǽ����ݴ�ŵ��� ͬ�����ݿ�������С�
��ν������ݿ��֣�
- ��ֱ��֣���ָ������ģ���֣�������Խ�Ⱥ����ر�����Ƭ��ر�����ڲ�ͬ�����ݿ��У����ַ�ʽ������ݿ�֮��ı��ṹ��ͬ��
- ˮƽ��֣���ˮƽ����ǽ�ͬһ���������ݽ��зֿ鱣�浽��ͬ�����ݿ��У���Щ���ݿ��еı��ṹ��ȫ��ͬ��
һ�㶼���Ƚ��д�ֱ��֣���Ϊ���ַ�ʽ��ַ�ʽʵ�������Ƚϼ����ݱ������ʲ�ͬ�����ݿ�Ϳ����ˡ����Ǵ�ֱ��ַ�ʽ�����ܳ��������ѹ���� �⣬���⣬ҲҪ��Ӧ�������Ƿ�������ֲ�ַ�ʽ��������ʵĻ���Ҳ�ܺܺõ���ɢ���ݿ�ѹ�������á�������ڶ����ұȽ��ʺϲ��ô�ֱ��֣� ��Ϊ����ĸ�����ҵ��/ģ�飨�鼮����Ӱ�����֣���Զ��������ݵ������ٶ�Ҳ�Ƚ�ƽ�ȡ���ͬ���ǣ��������ĺ���ҵ��������û��ϴ�����Ƭ������Ƭ���ݵ��� ���ٶ������û���������Խ��Խ�졣ѹ�������϶�����Ƭ���ϣ���Ȼ��ֱ��ֲ����ܴӸ����Ͻ�����ǵ����⣬���ԣ�Yupoo����ˮƽ��ֵķ�ʽ��
ˮƽ���ʵ��������Ը��ӣ�����Ҫ��ȷ��һ����ֹ���Ҳ���ǰ�ʲô���������ݽ����з֡� һ��2.0��վ�����û�Ϊ���ģ����ݻ����������û��������û�����Ƭ�����Ѻ����۵ȵȡ����һ���Ƚ���Ȼ��ѡ���Ǹ����û����з֡�ÿ���û�����Ӧһ������ �⣬����ij���û�������ʱ�� Ҫ��ȷ����/������Ӧ�����ݿ⣬Ȼ�����ӵ������ݿ����ʵ�ʵ����ݶ�д����ô����ô����Ӧ�û������ݿ��أ�Yupoo����Щѡ��
1�����㷨��Ӧ
����㷨�ǰ��û�ID����ż������Ӧ��������ID���û���Ӧ�����ݿ�A����ż��ID���û����Ӧ�����ݿ�B�������������������ǣ�ֻ�ֳܷ��� ���⡣��һ���㷨�ǰ��û�ID���������Ӧ������ID��0-10000֮����û���Ӧ�����ݿ�A�� ID��10000-20000�����Χ�Ķ�Ӧ�����ݿ�B���Դ����ơ����㷨��ʵ�������ȽϷ��㣬Ҳ�Ƚϸ�Ч�����Dz������������������Ҫ�������Ҫ���� ���ݿ�ڵ㣬��������㷨���ƶ��ܴ�����ݼ��� �Ƚ��������ڲ�ֹͣ�����ǰ���½����������ݿ�ڵ㡣
2��������/ӳ�����Ӧ
���ַ�����ָ����һ��������������ÿ���û���ID�����ݿ�ID�Ķ�Ӧ��ϵ��ÿ�ζ�д�û�����ʱ�ȴ��������ȡ��Ӧ���ݿ⡣���û�ע��������п��� �����ݿ��������ѡһ��Ϊ�佨�����������ַ����Ƚ����кܺõ������ԡ�һ��ȱ����������һ�����ݿ���ʣ�����������û�а��㷨��Ӧ�á�
�Ƚ�֮��Yupoo���õ����������ķ�ʽ������Ը��Ϊ���������ʧһЩ���ܣ����ο����ǻ���memcached�� ��Ϊ�������ݻ�������ı��Ե�ʣ����������ʷdz��ߡ������ܴܺ�̶��ϼ�����������ʧ��
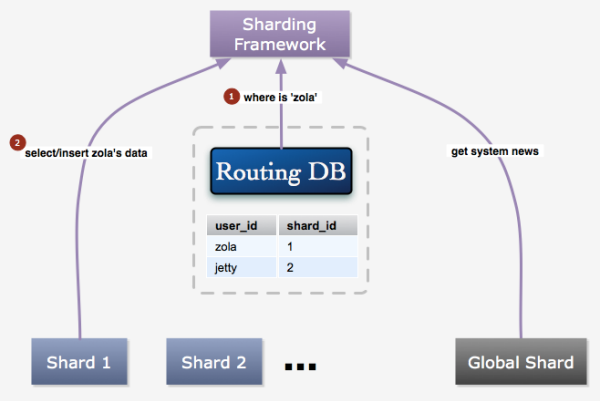
�������ķ�ʽ�ܹ��ȽϷ�����������ݿ�ڵ㣬�����ӽڵ�ʱ��ֻҪ�������ӵ��������ݿ��б��T�ɡ� ��Ȼ�����Ҫƽ������ڵ��ѹ���Ļ���������Ҫ�������ݵ�Ǩ�ƣ��������ʱ���Ǩ���������ģ��������С�ҪǨ���û�A�����ݣ�����Ҫ����״̬��ΪǨ�� �����У����״̬���û����ܽ���д����������ҳ���Ͻ�����ʾ�� Ȼ���û�A������ȫ�����Ƶ������ӵĽڵ��Ϻ���ӳ�����Ȼ���û�A��״̬��Ϊ���������ԭ����Ӧ�����ݿ��ϵ�����ɾ�����������ͨ�������ٳ��� �У����ԣ����Ժ��ٻ����û�����Ǩ�������е��������Ȼ����Щ�����Dz�����ij���û��ģ�����ϵͳ��Ϣ�����õȵȣ�����Щ���ݱ�����һ��ȫ�ֿ��С�
�ֿ������������ν����
�ֿ�����Ӧ�õĿ����Ͳ����϶������ܶ��鷳��
1������ִ�п��Ĺ�����ѯ
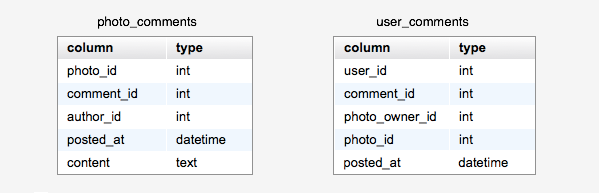
���������Ҫ��ѯ�����ݷֲ��ڲ�ͬ�����ݿ⣬û�취ͨ��JOIN�ķ�ʽ��ѯ��á�����Ҫ��ú��ѵ�������Ƭ�����ܱ�֤�� �к��ѵ����ݶ���ͬһ�����ݿ��һ������취��ͨ����β�ѯ���ٽ��оۺϵķ�ʽ��������Ҫ�����������Ƶ�������Щ�������ͨ��������������������� ��User-A��User-B�����ݿ�ֱ���DB-1��DB-2�� ��User-A������User-B����Ƭʱ�����ǻ�ͬʱ��DB-1��DB-2�б�������������Ϣ������������DB-2�е�photo_comments�� �в���һ���µļ�¼��Ȼ����DB-1�е�user_comments���в���һ���µļ�¼�����������Ľṹ����ͼ��ʾ���������ǿ���ͨ����ѯ photo_comments���õ�User-B��ij����Ƭ���������ۣ� Ҳ����ͨ����ѯuser_comments�����User-A���������ۡ�������Կ���ʹ��ȫ�ļ������������ijЩ���� ʹ��Solr���ṩȫվ��ǩ��������Ƭ��������
2�����ܱ�֤���ݵ�һ��/������
��������û�����Լ����Ҳû������֤�����������������Ƭ�����ӣ� �ܿ��ܳ��ֳɹ�����photo_comments�������Dz���user_comments��ʱȴ�����ˡ�һ���취�����������϶���������Ȼ���Ȳ��� photo_comments���ٲ���user_comments�� Ȼ���ύ������������취Ҳ������ȫ��֤���������ԭ���ԡ�
3�����в�ѯ�����ṩ���ݿ�����
����Ҫ�鿴һ����Ƭ����ƾһ����ƬID�Dz����ģ��������ṩ�ϴ�������Ƭ���û���ID��Ҳ�������ݿ��������������ҵ��� ʵ�ʵĴ��λ�á���ˣ�����������ƺܶ�URL��ַ������Щ�ϵĵ�ַ�����ֱ��뱣֤����Ȼ��Ч��Yupoo����Ƭ��ַ�ij�/photos /{username}/{photo_id}/����ʽ��Ȼ�����ϵͳ����ǰ�ϴ�����ƬID�� ������һ��ӳ���������photo_id��user_id�Ķ�Ӧ��ϵ���������ϵ���Ƭ��ַʱ��ͨ����ѯ���ű�����û���Ϣ, Ȼ�����ض����µĵ�ַ��
4������ID�ظ�������
���Ҫ�ڽڵ����ݿ���ʹ�������ֶΣ���ô���ǾͲ��ܱ�֤ȫ��Ψһ������Ǻ����ص����⣬���ǵ��ڵ�֮������ݷ�����ϵ ʱ���ͻ�ʹ�������ñȽ��鷳���������������ᵽ�����۵����ӡ����photo_comments���е�comment_id�������ֶΣ���������DB- 2.photo_comments�������µ�����ʱ�� �õ�һ���µ�comment_id������ֵΪ101����User-A��IDΪ1����ô���ǻ���Ҫ��DB-1.user_comments���в���(1, 101 ��)�� User-A�Ǹ��ܻ�Ծ���û�������������User-C����Ƭ����User-C�����ݿ���DB-3�� ���ɵ������������۵�IDҲ��101������������ÿ��ܷ�������ô��������DB-1.user_comments���в���һ��������(1, 101 ��)�����ݡ� ��ô����Ҫ��ô����user_comments���������أ���ʶһ�����ݣ������Բ��谡�����ҵ����е�ʱ��ܡ������ԭ�������á���ô������ user_id�� comment_id��photo_idΪ�������������photo_idҲ�п���һ������ȷ���ɣ�������ֻ���ټ���photo_owner_id�ˣ� ������������������ʵ���е������ܣ�̫���ӵ���ϼ���д��ʱ�����һ��������Ӱ�죬��������Ȼ��������Ҳ�ܲ���Ȼ�����ԣ�Yupoo�������ڽڵ���ʹ �������ֶΣ���취����ЩID���ȫ��Ψһ��Ϊ��������һ��ר����������ID�����ݿ⣬������еı��ṹ���ܼ�ֻ��һ�������ֶ�id�� ������Ҫ�����µ�����ʱ����������ID���photo_comments�������һ���յļ�¼���Ի��һ��Ψһ������ID�� ��Ȼ��Щ�����Ѿ���װ�����ǵĿ�����ˣ����ڿ�����Ա�����ġ� Ϊʲô�������������أ�����һЩ֧��incr������Key-Value���ݿ⡣Yupoo���DZȽϷ��İ����ݷ���MySQL� ���⣬Yupoo�ᶨ������ID������ݣ��Ա�֤��ȡ��ID��Ч�ʡ�
���ݿ��Ż���ʵ��
ǰ���ᵽ��һ�����ݿ�ڵ�ΪShard��һ��Shard������̨������������ɣ� ��������ΪNode-A��Node-B��Node-A��Node-B֮�������ó�Master-Master����Ƶġ� ��Ȼ��Master-Master�IJ���ʽ������ͬһʱ�仹��ֻʹ������һ����ԭ���Ǹ��Ƶ��ӳ����⣬ ��Ȼ��WebӦ����������û��Ự�����һ��A��B����֤ͬһ�û�һ�λỰ��ֻ����һ�����ݿ⣬ �������Ա���һЩ�ӳ����⡣����Python������û���κ�״̬�ģ����ܱ�֤��PHPӦ�ö�д��ͬ�����ݿ⡣��ôΪʲô�����ó�Master-Slave �أ�Yupoo����ֻ��һ̨̫�˷��ˣ�������ÿ̨�������϶�������������ݿ⡣ ����ͼ��ʾ����Node-A��Node-B�����Ƕ�������shard_001��shard_002���������ݿ⣬ Node-A�ϵ�shard_001��Node-B�ϵ�shard_001���һ��Shard����ͬһʱ��ֻ��һ�������ݿ��Active״̬�� ���ʱ�������Ҫ����Shard-001������ʱ���������ӵ���Node-A�ϵ�shard_001�� ������Shard-002��������������Node-B�ϵ�shard_002�������ֽ���ķ�ʽ��ѹ����ɢ��ÿ̨�����������ϡ� ��Master-Master��ʽ�������һ���ô��ǣ����Բ�ֹͣ���������½��б��ṹ������ ����ǰ��ֹͣ���ƣ�����Inactive�Ŀ⣬Ȼ������Ӧ�ã��ٽ��Ѿ������õ����ݿ��л���Active״̬�� ԭ����Active���ݿ��л���Inactive״̬��Ȼ���������ı��ṹ�����ָ����ơ� ��Ȼ������費һ���ʺ������������̣�������ṹ�ĸ��Ļᵼ�����ݸ���ʧ�ܣ���ô������Ҫֹͣ�����������ġ�
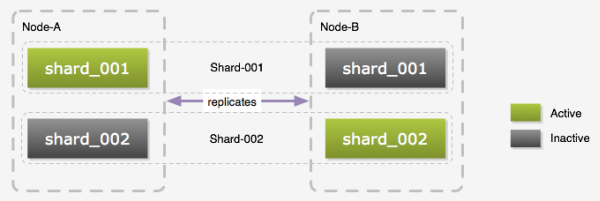
ǰ���ᵽ�����ӷ�����ʱ��Ϊ�˱�֤���ص�ƽ�⣬��ҪǨ��һ�������ݵ��µķ������ϡ�Ϊ�˱��������Ǩ�Ƶı�Ҫ����ʵ�ʲ� ���ʱ��ÿ̨�����ϲ�����8�������ݿ⣬ ���ӷ�������ֻҪ����Щ�����ݿ�Ǩ�Ƶ��·������Ϳ����ˡ������ÿ������һ���ķ������� Ȼ��ÿ̨��1/2������Ǩ�Ƶ�һ̨�·������ϣ������ܺܺõ�ƽ�⸺�ء���Ȼ�������ÿ̨��ֻ��һ������ʱ��Ǩ�ƾ��������ˣ�������Ӧ���DZȽϾ� Զ�������ˡ�
Yupoo�ѷֿ�������װ�����ǵ�PHP������ˣ�������Ա�����ϲ���Ҫ����Щ�������������š�������ʹ�ÿ�ܽ�����Ƭ���ݵĶ�д��һЩ���ӣ�
array('type' => 'long', 'primary' => true, 'global_auto_increment' => true),
'user_id' => array('type' => 'long'),
'title' => array('type' => 'string'),
'posted_date' => array('type' => 'date'),
));
$photo = $Photos->new_object(array('user_id' => 1, 'title' => 'Workforme'));
$photo->insert();
// ����IDΪ10001����Ƭ��ע���һ������Ϊ�û�ID
$photo = $Photos->load(1, 10001);
// ������Ƭ����
$photo->title = 'Database Sharding';
$photo->update();
// ɾ����Ƭ
$photo->delete();
// ��ȡIDΪ1���û���2010-06-01֮���ϴ�����Ƭ
$photos = $Photos->fetch(array('user_id' => 1, 'posted_date__gt' => '2010-06-01'));
?>
����Ҫ����һ��ShardedDBTable�������е�API����ͨ��������š���һ�������Ƕ����������ƣ� �����������Ѿ����ڣ���ô������֮ǰ����Ķ�����Ҳ����ͨ��get_table(��Photos��)�����������ȡ֮ǰ�����Table���� �ڶ��������Ƕ�Ӧ�����ݿ�����������������������ݿ������ֶΣ���ᷢ���ں��������API��ȫ����Ҫָ������ֶε�ֵ�� ���ĸ��������ֶζ��壬����photo_id�ֶε�global_auto_increment���Ա���Ϊtrue�������ǰ����˵��ȫ������ID�� ֻҪָ����������ԣ���ܻᴦ����ID�����顣
�������Ҫ����ȫ�ֿ��е����ݣ�������Ҫ����һ��DBTable����
array('type' => 'long', 'primary' => true, 'auto_increment' => true),
'username' => array('type' => 'string'),
));
?>
DBTable��ShardedDBTable�ĸ��࣬���˶���ʱ������Щ��ͬ��DBTable����Ҫָ�����ݿ������ֶΣ��������ṩһ����API��
�������淽����ѡ��
Yupooʹ�õĿ���Դ����湦�ܣ��Կ�����Ա�����ġ�
load(1, 10001); ?>
��������ķ������ã�����ȳ�����Photos-1-10001ΪKey�ڻ����в��ң�δ�ҵ��Ļ���ִ�����ݿ��ѯ�����뻺�档��������Ƭ���Ի�ɾ����Ƭʱ����ܸ���ӻ�����ɾ������Ƭ�����ֵ�������Ļ���ʵ�������Ƚϼ����鷳�����������������б���ѯ����Ļ��档
fetch(array('user_id' => 1, 'posted_date__gt' => '2010-06-01'));
?>
Yupoo�������ѯ�ֳ���������һ���Ȳ��������������ƬID��Ȼ���ٸ�����ƬID�ֱ���Ҿ������Ƭ��Ϣ�� ��ô�����Ը��õ����û��档��һ����ѯ�Ļ���KeyΪPhotos-list-{shard_key}-{md5(��ѯ����SQL���)}�� Value����ƬID�б������ż����������shard_keyΪuser_id��ֵ1��Ŀǰ�������б�����Ҳ���鷳�� ��������û�����ij����Ƭ���ϴ�ʱ���أ����ʱ���е����ݾͲ�һ�����������ˡ����ԣ���Ҫһ����������֤���Dz���ӻ����еõ����ڵ��б����ݡ����� Ϊÿ�ű�������һ��revision�����ñ������ݷ����仯ʱ������insert/update/delete�������� ���Ǿ�������revision���������ǰ��б��Ļ���Key��ΪPhotos-list-{shard_key}-{md5(��ѯ����SQL�� ��)}-{revision}�� �������ǾͲ����ٵõ������б��ˡ�
revision��ϢҲ�Ǵ���ڻ�����ģ�KeyΪPhotos-revision�����������������������Ǻ����б��� ��������ʲ���̫�ߡ���Ϊ�������������������͵�revisionΪ����Key�ĺ�����Ȼ���revision���µķdz�Ƶ�����κ�һ���û��Ļ��ϴ� ����Ƭ���ᵼ�����ĸ��£������Ǹ��û�������������Ҫ��ѯ��Shard�Ҫ�����û��Ķ����������û���Ӱ�죬���ǿ���ͨ����Сrevision�����÷� Χ���ﵽ���Ŀ�ġ� ����revision�Ļ���Key���Photos-{shard_key}-revision�������Ļ���IDΪ1���û�����������Ƭ��Ϣʱ�� ֻ�����Photos-1-revision���Key����Ӧ��revision��
��Ϊȫ�ֿ�û��shard_key����������ȫ�ֿ��еı���һ�����ݣ����ǻᵼ���������Ļ���ʧЧ�� ���Ǵ�����£����ݶ���������Χ�ģ����������̳���������ӣ� �����������⡣��������һ�������һ�����ӣ�û��Ҫʹ������������ӻ��涼ʧЧ�� ������DBTable��������һ����isolate_key�����ԡ�
array('type' => 'long', 'primary' => true),
'post_id' => array('type' => 'long', 'primary' => true, 'auto_increment' => true),
'author_id' => array('type' => 'long'),
'content' => array('type' => 'string'),
'posted_at' => array('type' => 'datetime'),
'modified_at' => array('type' => 'datetime'),
'modified_by' => array('type' => 'long'),
), 'topic_id');
?>
ע��캯�������һ������topic_id����ָ���ֶ�topic_id��Ϊisolate_key���������ú�shard_keyһ�����ڸ���revision�����÷�Χ��
ShardedDBTable�̳���DBTable������Ҳ����ָ��isolate_key�� ShardedDBTableָ����isolate_key�Ļ����ܹ����������Сrevision�����÷�Χ�� ����������Ƭ�Ĺ�����yp_album_photos�����û�����������һ��������������µ���Ƭʱ�� �ᵼ������������Ƭ�б�����ҲʧЧ�����ָ�����ű���isolate_keyΪalbum_id�Ļ��� ���ǾͰ�����Ӱ���������˱�����ڡ�
�����Ϊ��������һ��ֻ��һ��PHP���飬��Ч��Χ��Request�����ڶ�����memcached����ô����ԭ���ǣ� �ܶ�������һ��Request��������Ҫ���ض�Σ��������Լ���memcached��������������Yupoo�Ŀ��Ҳ�ᾡ���ܵķ���memcached ��gets��������ȡ���ݣ� �Ӷ�������������
�ο����£�http://www.infoq.com/cn/articles/yupoo-partition-database
���ԣ�http://www.biaodianfu.com/yupoo-architecture.html