 3G Eden
3G Eden RSS
RSS我知道一些人会立刻抱怨。许多第三方库都可以简化此代码 — JDOM 和 dom4j 是其中最流行的两个。但是,任何 Java 库都无法与使用 Groovy MarkupBuilder 的简洁性相比,如清单 7 所示:
清单 7. 使用 Groovy 创建 XML
def xml = new groovy.xml.MarkupBuilder()
xml.langs(type:"current"){
language("Java")
language("Groovy")
language("JavaScript")
}
|
注意到这与 XML 代码的比率又重新回到了将近 1:1。更加重要的是,我可以再次查看 XML。当然,尖括号已经被替换为大括号,并且属性使用冒号(Groovy 的 HashMap 符号)而不是等号,但其基本结构在 Groovy 或 XML 中都是可以辨认的。它几乎类似于一个用于构建 XML 的 DSL,您认为呢?
Groovy 能够实现这种 Builder 魔法,因为它是一种动态的语言。另一方面,Java 语言则是静态的:Java 编译器将确保所有方法在您调用它们之前都是确实存在的。(如果您尝试调用不存在的方法,Java 代码甚至不进行编译,更不用说运行了。)但是,Groovy 的 Builder 证明,某种语言中的 bug 正是另一种语言的特性。如果您查阅 API 文档中的 MarkupBuilder 相关部分,您会发现它没有 langs() 方法、language() 方法或任何其他元素名称。幸运的是,Groovy 可以捕获这些不存在的方法调用,并采取一些有效的操作。对于 MarkupBuilder 的情况,它使用 phantom 方法调用并生成格式良好的 XML。
清单 8 对我刚才给出的简单的 MarkupBuilder 示例进行了扩展。如果您希望在 String 变量中捕获 XML 输出,则可以传递一个 StringWriter 到 MarkupBuilder 的构造函数中。如果您希望添加更多属性到 langs 中,只需要在传递时使用逗号将它们分开。注意,language 元素的主体是一个没有前置名称的值。您可以在相同的逗号分隔的列表中添加属性和主体。
清单 8. 经过扩展的 MarkupBuilder 示例
def sw = new StringWriter()
def xml = new groovy.xml.MarkupBuilder(sw)
xml.langs(type:"current", count:3, mainstream:true){
language(flavor:"static", version:"1.5", "Java")
language(flavor:"dynamic", version:"1.6.0", "Groovy")
language(flavor:"dynamic", version:"1.9", "JavaScript")
}
println sw
//output:
<langs type='current' count='3' mainstream='true'>
<language flavor='static' version='1.5'>Java</language>
<language flavor='dynamic' version='1.6.0'>Groovy</language>
<language flavor='dynamic' version='1.9'>JavaScript</language>
</langs>
|
通过这些 MarkupBuilder 技巧,您可以实现一些有趣的功能。举例来说,您可以快速构建一个格式良好的 HTML 文档,并将它写出到文件中。清单 9 显示了相应的代码:
清单 9. 通过 MarkupBuilder 构建 HTML
def sw = new StringWriter()
def html = new groovy.xml.MarkupBuilder(sw)
html.html{
head{
title("Links")
}
body{
h1("Here are my HTML bookmarks")
table(border:1){
tr{
th("what")
th("where")
}
tr{
td("Groovy Articles")
td{
a(href:"http://ibm.com/developerworks", "DeveloperWorks")
}
}
}
}
}
def f = new File("index.html")
f.write(sw.toString())
//output:
<html>
<head>
<title>Links</title>
</head>
<body>
<h1>Here are my HTML bookmarks</h1>
<table border='1'>
<tr>
<th>what</th>
<th>where</th>
</tr>
<tr>
<td>Groovy Articles</td>
<td>
<a href='http://ibm.com/developerworks'>DeveloperWorks</a>
</td>
</tr>
</table>
</body>
</html>
|
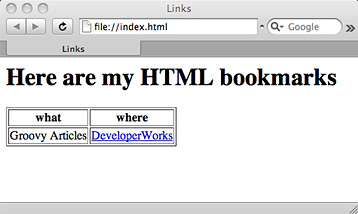
图 1 显示了清单 9 所构建的 HTML 的浏览器视图:
图 1. 呈现的 HTML
使用 StreamingMarkupBuilder 创建 XML
MarkupBuilder 非常适合用于同步构建简单的 XML 文档。对于更加高级的 XML 创建,Groovy 提供了一个 StreamingMarkupBuilder。通过它,您可以添加各种各样的 XML 内容,比如说处理指令、名称空间和使用 mkp 帮助对象的未转义文本(非常适合 CDATA 块)。清单 10 展示了有趣的 StreamingMarkupBuilder 特性:
清单 10. 使用 StreamingMarkupBuilder 创建 XML
def comment = "<![CDATA[<!-- address is new to this release -->]]>"
def builder = new groovy.xml.StreamingMarkupBuilder()
builder.encoding = "UTF-8"
def person = {
mkp.xmlDeclaration()
mkp.pi("xml-stylesheet": "type='text/xsl' href='myfile.xslt'" )
mkp.declareNamespace('':'http://myDefaultNamespace')
mkp.declareNamespace('location':'http://someOtherNamespace')
person(id:100){
firstname("Jane")
lastname("Doe")
mkp.yieldUnescaped(comment)
location.address("123 Main")
}
}
def writer = new FileWriter("person.xml")
writer << builder.bind(person)
//output:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type='text/xsl' href='myfile.xslt'?>
<person id='100'
xmlns='http://myDefaultNamespace'
xmlns:location='http://someOtherNamespace'>
<firstname>Jane</firstname>
<lastname>Doe</lastname>
<![CDATA[<!-- address is new to this release -->]]>
<location:address>123 Main</location:address>
</person>
|
注意,StreamingMarkupBuilder 直到您调用 bind() 方法时才会生成最终的 XML,该方法将接受标记和所有指令。这允许您异步构建 XML 文档的各个部分,并同时输出它们。(参见 参考资料 了解更多信息。)
理解 XmlParser
Groovy 为您提供了两种生成 XML — MarkupBuilder 和 StreamingMarkupBuilder 的方式 — 它们分别具备不同的功能。解析 XML 也同样如此。您可以使用 XmlParser 或者 XmlSlurper。
XmlParser 提供了更加以程序员为中心的 XML 文档视图。如果您习惯于使用 List 和 Map(分别对应于 Element 和 Attribute)来思考文档,则应该能够适应 XmlParser。清单 11 稍微解析了 XmlParser 的结构:
清单 11. XmlParser 详细视图
def xml = """
<langs type='current' count='3' mainstream='true'>
<language flavor='static' version='1.5'>Java</language>
<language flavor='dynamic' version='1.6.0'>Groovy</language>
<language flavor='dynamic' version='1.9'>JavaScript</language>
</langs>
"""
def langs = new XmlParser().parseText(xml)
println langs.getClass()
// class groovy.util.Node
println langs
/*
langs[attributes={type=current, count=3, mainstream=true};
value=[language[attributes={flavor=static, version=1.5};
value=[Java]],
language[attributes={flavor=dynamic, version=1.6.0};
value=[Groovy]],
language[attributes={flavor=dynamic, version=1.9};
value=[JavaScript]]
]
]
*/
|
注意,XmlParser.parseText() 方法返回了一个 groovy.util.Node — 在本例中是 XML 文档的根 Node。当您调用 println langs 时,它会调用 Node.toString() 方法,以便返回调试输出。要获取真实数据,您需要调用 Node.attribute() 或者 Node.text()。
使用 XmlParser 获取属性
如前所述,您可以通过调用 Node.attribute("key") 来获取单独的属性。如果您调用 Node.attributes(),它会返回包含所有 Node 的属性的 HashMap。使用您在 “for each 剖析” 一文中所掌握的 each 闭包,遍历每个属性简直就是小菜一碟。清单 12 显示了一个相应的例子。(参见 参考资料,获取关于 groovy.util.Node 的 API 文档。)