 Linuxeden开源社区
Linuxeden开源社区作者
2017年4月18日和19日,Facebook在San Jose召开了一年一度的F8大会,本次大会通过Facebook Live进行了直播。Designing for Scale的博主Wissam Abirached通过Facebook Live观看了这届F8大会,他对Facebook Live是如何扩展以支持F8的这个问题产生了十分浓厚的兴趣,因此撰写了一篇名为《How Facebook Live Scales》的文章,由此也引出了Facebook Live的很多细节。
早在2015年底,Facebook的工程师就在《Under the hood: Broadcasting live video to millions》一文中介绍了Faceook Live的一些细节。Facebook拥有庞大的用户群,在面对流量尖刺的同时,还要尽可能降低延时以带来更强的参与感,他们遇到了什么问题,又是如何解决的呢?
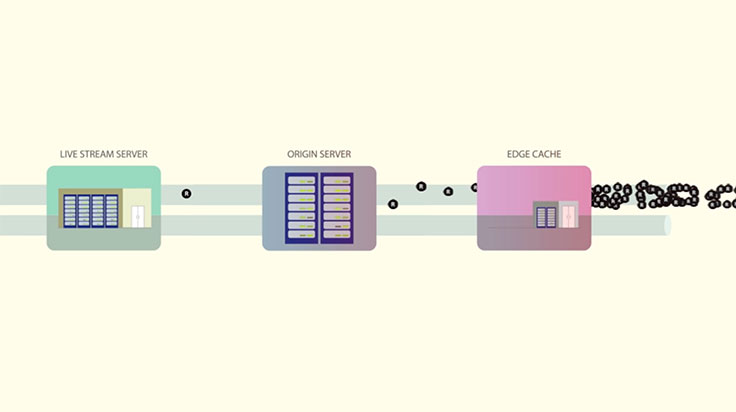
首先是“惊群问题”(Thundering Herd Problem),它会造成延时、丢帧,甚至是掉线,为了避免直播流服务器(Live Stream Server)被大量请求冲垮,Facebook构建了由直播流服务器、源服务器(Origin Server)和边缘缓存(Edge Cache)组成的三层结构。用户访问最近的边缘缓存,边缘缓存负责回源,源服务器向直播流服务器取得实际的内容。
Facebook的Arun Moorthy在《Connecting the World: A look inside Facebook’s Networking Infrastructure》中对Facebook的全球节点做过介绍,数据中心主要在北美和欧洲,而边缘节点更是几乎遍布全球(除了南北极),加之还有自己定制的服务器、机柜与网络结构。在这样的基础设施支持下,Facebook Live的服务器能尽可能地靠近用户。
如果某个边缘缓存负载过高,负载均衡器会将请求重定向到离该节点最近的另一个尚可提供服务的边缘缓存上,负载均衡器能够预测目标节点的负载情况,这是一个非常实用的功能。
在这种情况下,仍然会有1.8%的请求透过边缘缓存落到源服务器上,在海量请求下,1.8%也是一个很大的数字。为了应对这个问题,边缘缓存只会让第一个请求回源,其他的相同请求则放在一个队列中,等第一个请求的结果返回了,它们也就不用再回源了。源服务器上也有类似的请求合并回源处理机制。Wissam Abirached在文章中提到,如果使用Nginx,可以将proxy_cache_lock设置为on开启请求合并功能。
另一方面,为了让直播的感受更加实时,Facebook使用RTMP流协议每隔2到3秒就传输一次数据,RTMP通过播放器与服务端的TCP长连接将音频与视频数据连续不断地推送给用户。在RTMP中,音频流与视频流是分开的,但都以4KB为单位,推模式与小数据块的结合,大大降低了延时,给用户带来更流畅的体验。
值得一提的是,国内的一些直播服务提供商也拥有与Facebook类似的架构,针对海量请求做了各种优化,可以说不亚于Facebook。比如,七牛云白顺龙的《移动CDN及直播性能优化》(这篇《七牛直播云性能优化实践》博客的内容也是一样的),又拍云黄慧攀的《云直播系统架构与实施》,两者都提到了类似Facebook的多层服务器结构和网络智能调度系统(可能大家在节点部署上略有不同,毕竟服务的目标更多是在国内),能够在极大程度上保证用户的体验。大家也都对直播常用的协议进行了说明,介绍了RTMP、HLS和HTTP-FLV,以及它们分别适用的场景,在各自系统中的位置。
此外,上述两个演讲中还提到了一些其他的优化,比如GOP缓存的权衡、多码率支持和HTTP-DNS等等,相信Facebook也有类似的处理。
如果您对Facebook Live的更多细节感兴趣,可以看看Facebook的Federico Larumbe在@Scale 2016上的这个演讲。在直播盛行的今天,相信一定有很多读者从事直播相关的工作,也欢迎大家分享自己的直播系统优化经验。
转自 http://www.infoq.com/cn/news/2017/05/Facebook-Live-way