 Linuxeden开源社区
Linuxeden开源社区作者
数据库管理系统(简称 DBMS)无疑是任何数据密集型应用程序当中最为重要的组成部分,其肩负着处理大量数据以及高复杂性工作负载的重任。然而,数据库管理系统本身却往往难于管理,因为其中通常包含数百种配置“旋钮”,用于控制诸如缓存内存分配量以及存储介质数据写入频率等要素。各类企业一般需要聘请专业人士以协助相关调配工作,但对于大多数企业而言,此类专业人才的开价亦相当高昂。
面对这一难题,卡耐基 – 梅隆大学数据库小组(Carnegie Mellon Database Group)的学生及研究人员们共同开发出一款名为 OtterTune 的新型工具,其能够以自动化方式识别出最适当当前数据库管理系统配置需求的设置组合。其目标在于有效简化用户对 DBMS 的部署流程,确保那些在数据库管理层面不具备任何专业知识的朋友亦能轻松完成任务。
OtterTune 与其它 DBMS 配置工具之间的主要差别在于,其能够利用自此前 DBMS 部署工作当中积累到的知识指导新系统的配置工作。这一设计思路显然降低了新 DBMS 部署方案在调整当中所需要的时间与资源投入。而为了实现这一目标,OtterTune 专门建立起一套数据库,用以收集从此前调节会话中提取到的重要信息。其利用这部分数据建立机器学习(简称 ML)模型,用以捕捉 DBMS 在面对不同配置方案时作出怎样的响应。OtterTune 还利用这些模型以指导新型应用程序的配置实验,并提供推荐设置以提升目标运作效果(例如减少延迟或者提高数据吞吐量)。
在今天的文章中,我们将探讨 OtterTune 机器学习管道当中的每个组成部分,同时展示其如何彼此交互以实现 DBMS 配置调节。在此之后,我们还将立足 MySQL 与 PostgreSQL 评估 OtterTune 的调节效果,包括将其最佳配置方案与数据库管理员(简称 DBA)以及其它自动化调节工具给出的答案进行比对。
OtterTune 是一款开源工具,由卡耐基 – 梅隆大学数据库小组的学生及研究人员们共同开发而成。其全部代码皆可点击此处通过 GitHub 访问,且基于 Apache License 2.0 许可。
OtterTune 工作原理解析
以下示意图用于解释 OtterTune 中的各组件与工作流。
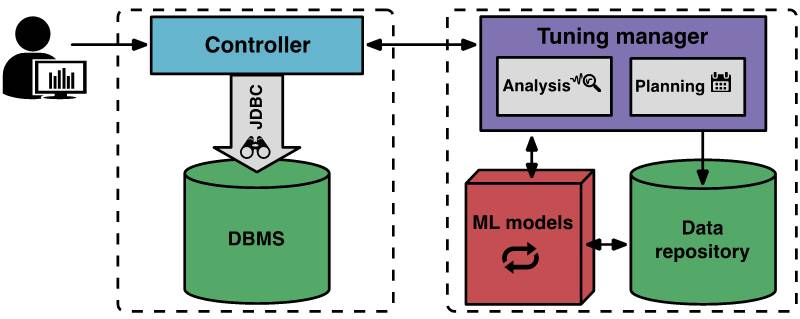
在开始一轮新的调节会话时,用户首先需要告知 OtterTune 此番优化的具体目标(例如面向延迟抑或数据吞吐量)。其客户端控制器将接入目标 DBMS 并收集其 Amazon EC2 实例类型与当前配置等相关信息。
在此之后,该控制器会开始第一轮观察周期,在此期间其将观察 DBMS 以及与既定目标相关之各项记录。在此轮观察周期结束后,控制器将从 DBMS 当中收集各类内部指标,例如 MySQL 自磁盘处读取之页面以及向磁盘中写入之页面计数。该控制器随后会将目标信息与内部指标发送回调节管理器当中。
当 OtterTune 的调节管理器接收到这些指标后,其会将相关数据存储在自有存储库内。OtterTune 利用这些结果计算出控制器应在目标 DBMS 上安装的下一套配置方案。具体配置方案由调节管理器交付至控制器处,同时确定运行后的预期改进效果。这时,用户即可决定继续抑或中止当前调节会话。
注意事项
OtterTune 为其支持的每个 DBMS 版本皆设立有一套调节黑名单。此份黑名单中囊括了各类无法调整的项目(例如 DBMS 存储文件的路径名称)或者可能引发严重乃至隐藏后果的选项(例如可能导致 DBMS 遭遇潜在数据丢失)。每开始一项调节会话时,OtterTune 即可弹出黑名单提示,用以提醒用户添加各项不希望由 OtterTune 进行调节的具体条目。
OtterTune 做出的某些假设可能会对部分用户产生一定的不利影响。举例来说,其假设用户拥有允许控制器对 DBMS 配置进行修改的管理权限。如果用户不具备此权限,则可在其它硬件之上部署一套数据库副本以执行 OtterTune 调节实验——但这亦要求用户重播工作负载追踪流程或立足生产 DBMS 进行查询转发。
机器学习管道
以下示意图介绍了数据如何经由 OtterTune 的机器学习管道实现移动与处理。全部观察结果皆被保留在 OtterTune 的存储库当中。
OtterTune 首先会将观察结果交付至 Workload Characterization 组件当中。此组件负责识别其中一小部分 DBMS 指标,从而更好地把握性能差异以及不同工作负载之间的区别性特征。
接下来,Knob Indetification 组件会生成一份与可调节项目相关之排名清单,其具体排序根据对 DBMS 性能之影响力而定。OtterTune 随后会将全部信息馈送至 Automatic Tuner 当中。此组件负责将目标 DBMS 的工作负载与现有数据存储库内最为相似的工作负载进行映射,而后利用对应工作负载数据以生成更适用的配置方案。
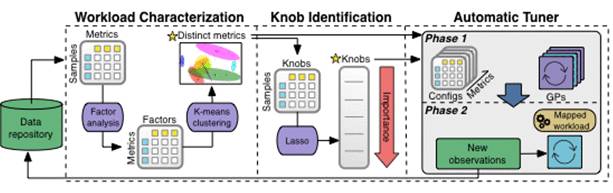
下面让我们深入了解机器学习管道当中所涉及的每一个组件。
Workload Characterization: OtterTune 利用 DBMS 的各内部运行时指标以表征某一工作负载的行为方式。这些指标能够对工作负载作出准确表示,因为其能够确切捕捉到其运行时行为当中的各项细节。然而,亦有许多度量完全不必要存在:其中一部分属于不同单元记录当中的同一量度结果,另一些不必要指标则代表着某些数值存在高度互关联性的 DBMS 独立组件。因此,对其中的冗余度量进行排除将非常重要,这将有效帮助我们降低机器学习模型的复杂性水平。为此,我们将面向 DBMS 对相关模型的度量进行收敛。此后,我们将从每个群集当中选择出一个代表性度量,并确保其为最靠近群集中心的度量。机器学习管道当中的后续组件将对这些度量加以使用。
Knob Identification: DBMS 可以拥有数百项可调节项目,但其中只有一个子集会对 DBMS 性能造成实际影响。OtterTune 利用当前流行趋势 特性选择技术 Lasso 以确保哪个条目会对系统的整体性能造成严重影响。通过此项技术,OtterTune 将能够利用其存储库内的数据对各 DBMS 可调节项目的重要性进行排序。
除此之外,OtterTune 还必须决定在配置建议当中具体包含多少个可调节项目。很明显,包含太多可调节项目将显著增加 OtterTune 的优化时长,但太少则可能导致 OtterTune 找不到最佳配置方案。为了以自动化方式实现此流程,OtterTune 采取了增量式方法。其会逐渐增加调节会话当中所使用的条目数量。此种方法能够确保 OtterTune 在扩展其调节范围之前,首先识别并优化一小部分最为重要的配置调节项目。
Automatic Tuner: Automated Tuning 组件通过在每轮观察周期之后执行两项分析步骤以确定 OtterTune 的推荐配置方案。
首先,该系统利用确定自 Workload Characterization 组件中识别指标的性能数据从原有存储库内找到最能体现目标 DBMS 工作负载特征的原有调节会话。其会将两项会话间的指标进行比较,旨在了解如何对不同调节选项进行变动以实现类似的工作负载指标量化结果。
在此之后,OtterTune 会选择另一套调节配置进行尝试。这套新的配置方案切合当前统计模型所收集到的实际数据,即以此数据为基础从存储库当中查找类似的工作负载。这套模型允许 OtterTune 预测 DBMS 在各类潜在配置下的实际运行效果 OtterTune 会对下一套配置进行优化,从而将探索(即收集集团以改进模型)转化为实际利用(尽可能带来更出色的目标度量)。
具体实现
OtterTune 以 Python 语言编写而成。
对于 Workload Characterization 与 Knob Identification 两种组件,运行时性能并非我们的关注重点,因此我们使用 scikit 以实现相应的机器学习算法。这些算法在后台进程当中运行,并使用来自 OtterTune 存储库的新数据。
对于 Automatic Tuner,这些机器学习算法则变得更为关键。其需要在每一轮观察周期后运行,同时结合新数据以确保 OtterTune 能够选择一项对应调节条目进行下一步尝试。在这一流程中,由于性能成为更加重要的考量因素,因此我们使用 TensorFlow 以实现这些算法。
为了收集与 DBMS 硬件、调节配置以及运行时性能指标相关的数据,我们将 OtterTune 控制器同 OLTP-Bench 基准测试框架进行了整合。
实验性设计
为了完成评估,我们利用 OtterTune 所给出的以下最佳配置选项对 MySQL 及 Postgres 性能进行了比较:
- Default: DBMS 所提供的配置方案
- Tuning script: 由一款开源调节建议工具生成的配置方案
- DBA: 由人类数据库管理员选定的配置方案
- RDS: 针对 Amazon RDS 管理并部署在同一 EC2 实例类型之上的 DBMS 进行定制化的配置方案
我们在 Amazon EC2 现货实例之上进行了全部实验。我们分别在两套实例之上执行实验过程:其一作为 OtterTune 控制器,其二则作为目标 DBMS 部署系统。我们在这里分别使用了 m4.large 与 m3.xlarge 实例类型。我们将 OtterTune 的调节管理器与数据存储库部署在一套本地服务器之上,其配置为 20 计算核心与 128 GB 内存。
我们还用到了 TPC-C 工作负载,其属于业界标准的在线事务处理(简称 OLTP)系统性能评估工作负载类型。
评估方式
对于我们在实验当中所使用的 MySQL 与 Postgres 两套数据库,我们分别对其延迟水平与数据吞吐量进行了观察。以下图表给出了对应结果。第一份图表所示为第 99 百分位处的延迟水平,意味着“最坏情况”下完成事务处理所需要的时长。第二份图表则显示了数据吞吐量结果,即每秒完成的平均事务数量。
MySQL 测试结果
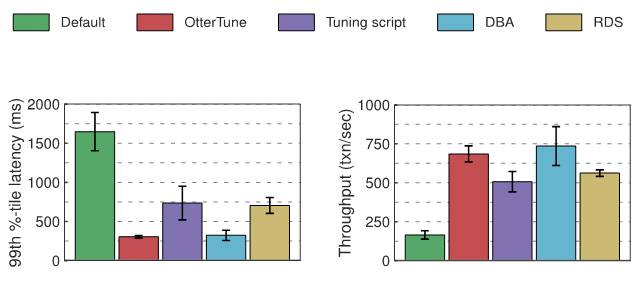
将 OtterTune 所生成的最佳配置与 Tuning Script 以及 RDS 相关配置进行比较可以发现,MySQL 在延迟水平方面降低了约 60%,而数据吞吐量则在 OtterTune 配置的帮助下提升 22% 到 35% 之间。与此同时,OtterTune 的生成的配置方案在实际效果上与人类数据库管理员几乎不相上下。
一部分特定 MySQL 调节项目对其 TPC-C 工作负载性能表现产生了显著影响。OtterTune 与数据库管理员提供的配置方案可为每一调节选项带来良好的设置效果。RDS 的执行水平稍差一点,在设置效果上略逊一筹。而 Tuning Script 的配置效果最差——因为其只对其中一个调节选项作出了变更。
Postgres 测试结果
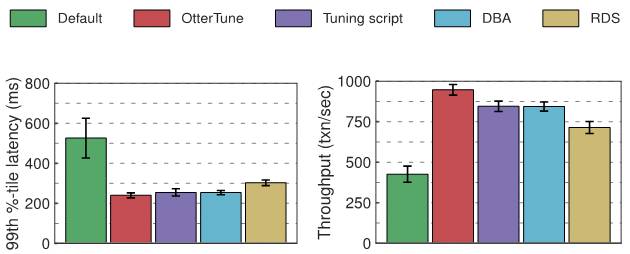
在延迟方面,OtterTune、调节工具、数据库管理员以及 RDS 所给出的配置建议全部优于 Postgres 的默认设置,且提升效果基本类似。我们可以将这一结果归结于 OLTP-Bench 客户端与 DBMS 之间的往返路由造成了巨大的性能影响。在数据吞吐量方面,Postgres 在使用 OtterTune 建议配置时,实际效果较数据库管理员及 Tuning Script 配置选项大约提升 12%,而与 RDS 间的比较优势更是达到 32%。
与 MySQL 类似,只有少数几个调节选项会对 Postgres 性能产生显著影响。OtterTune、数据库管理员、Tuning Script 以及 RDS 所生成的配置都对这些条目进行了修改,且其中多数能够带来相当不错的设置效果。
总结意见
OtterTune 能够以自动化方式为 DBMS 各配置选项找到良好的设置方式。为了对新的 DBMS 部署系统进行调整,OtterTune 会使用以往调优会话当中收集到的训练数据。由于 OtterTune 并不需要在每次生成操作当中再次利用初始数据集进行机器学习模型训练,因此整个调节时间周期得到大幅缩减。
未来的发展目标是什么?为了进一步适应日益普及的 DBaaS 部署场景(此类场景下,将无法以远程方式访问 DBMS 主机设备),OtterTune 将很快能够自动检测目标 DBMS 的硬件功能,且无需进行任何远程访问。
欲了解更多与 OtterTune 项目相关的细节信息,请点击此处参阅我们的论文(英文原文)或者 GitHub 上的代码。亦欢迎大家关注我们的网站,我们将尽快通过本网站以在线调优服务的形式将 OtterTune 交付到您的手中。
转自 http://www.infoq.com/cn/news/2017/06/Amazon-machine-tools-DBA-out