 Linuxeden开源社区
Linuxeden开源社区Google 工程师 Eric Biggers 近年来一直负责许多出色的 Linux 加密子系统性能优化,他还有另一个令人兴奋的补丁系列。Biggers 在优化现代 Intel/AMD CPU 的各种功能方面做了一些出色的工作,尤其是围绕 AVX-512 实现,现在他对 CRC32 校验和性能进行了另一项重大优化。
周六是 Eric Biggers 的新补丁系列,致力于提高至少 512 字节长度的 CRC32C 性能。这里的策略依赖于 AVX-512 在有能力的 CPU 上的 VPCLMULQDQ 向量无进位乘法。
在 Linux 内核邮件列表上的 这个补丁系列中,他解释说:
“当 CPU 支持 VPCLMULQDQ 并且具有 AVX-512 的”良好“实现时,使用 crc32_lsb_vpclmul_avx512() 而不是 crc32c_x86_3way() 来提高 crc32c() 在长度 >= 512 字节上的性能。目前,这意味着 AMD Zen 4 及更高版本,以及 Intel Sapphire Rapids 及更高版本。将 crc32_lsb_vpclmul_avx512() 所需的常量表传递给它使用 CRC-32C 多项式。
基本原理:VPCLMULQDQ 性能在较新的 CPU 上有所提高,使 crc32_lsb_vpclmul_avx512() 比 crc32c_x86_3way() 快,即使 crc32_lsb_vpclmul_avx512() 是为通用 32 位 CRC 设计的,并且不使用 x86_64 的专用 CRC-32C 指令。
最终结果?在采用“良好”AVX-512 实现的现代 Intel 和 AMD CPU 上,CRC32 性能有一些相当不错的加速:
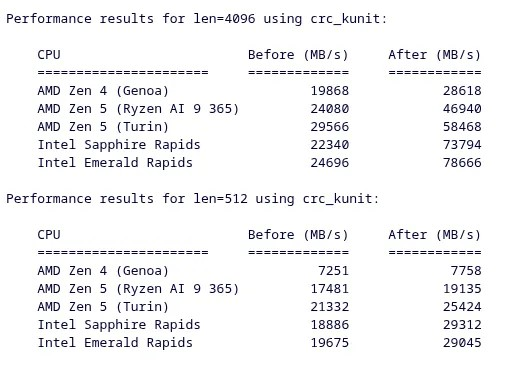
Eric Biggers 继续指出,即使使用最新的 Intel Xeon CPU,与使用最新的 AVX-512 和最新的 Intel 处理器相比,AMD 的 AVX-512 实现仍然具有更短的预热时间:
“话虽如此,在上述基准测试中,ZMM 寄存器是 ”热门“ 的,因此它们并不能完全说明全部情况。虽然与较旧的 Intel CPU 相比有了显著改进,但 Intel 仍然具有 ~2000 ns 的 ZMM 预热时间,其中 512 位指令的执行速度比正常情况慢 4 倍。相比之下,AMD 表现更好,ZMM 预热时间几乎为零(最多 ~60 ns)。因此,虽然这种变化对 AMD 总是有益的,但严格来说,在某些情况下它对 Intel 没有好处,例如少量带有“冷”ZMM 寄存器的 512 字节消息。但通常情况下,即使在 Intel 上也是有益的。
请注意,在 AMD Zen 3–5 上,crc32c() 性能可以通过交错 crc32q 和 VPCLMULQDQ 指令的实现得到进一步提高。不幸的是,在这些微架构中的*每一个*上,不同的此类实现似乎都是最佳的。这些改进留给未来的工作。此提交只是改进了我们选择已有实现的方式。
性能结果很好,希望这个 VPCLMULQDQ 优化的 crc32c() 代码能很快进入主线 Linux 内核,以进一步增强现代x86_64支持 AVX-512 的处理器。