 Linuxeden开源社区
Linuxeden开源社区作者
1、OpenStack Telemetry简介
OpenStack Telemetry项目是OpenStack big tent下负责计量统计的组件,目前Telemetry是包含了四个子项目,Ceilometer、 Aodh、Gnocchi和Panko。其中的Ceilometer项目是最早OpenStack项目中负责计量统计的服务,但是由于云平台数据收集越来越多造成CCCeilometer越来越复杂,因此在Mitaka版本开始ceilometer项目开始分解为不同项目,并统称为OpenStack Telemetry。
云监控告警服务,主要包括三个部分: 计量数据收集、计量数据存储、告警服务。
OpenStack Telemetry的架构如图所示(Mitaka版本),其中Ceilometer是负责数据收集,Gnocchi则负责meter数据存储,Aodh项目负责告警服务,Panko负责Event数据存储。由于Event和Meter两种数据类型不同,CCCeilometer社区将两种数据分开处理。由于Panko项目到newton才有release,而笔者采用的mitaka验证环境,本文中不涉及Panko。
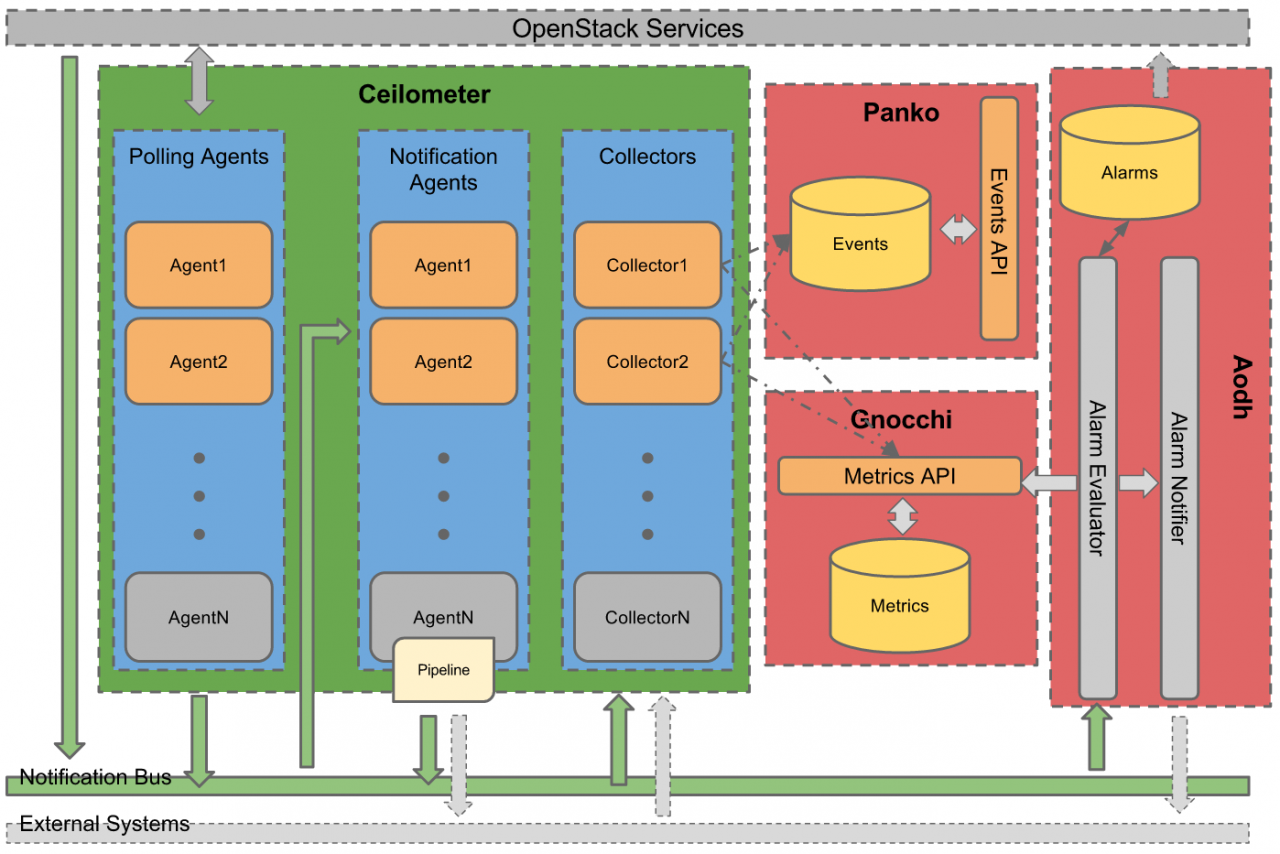
图 1 Telemetry逻辑架构
2、数据收集服务
Ceilometer服务主要用于数据收集,并提供两类数据的收集meter和Event。
- Meter数据由Ceilometer的polling agent主动获取。
- Event数据来源是OpenStack service 的notification,例如instance/volume/network 等创建更新删除等等。
a) polling agent:定期轮询获取监控数据并将数据发送给CCCeilometer notification agent做进一步处理,通过libvirt接口或者snmp或者OpenStack service API。
Polling agent又根据namespace做了metering的区分,分别对应不同的agent
- Central polling agent,主要是通过OpenStack API 进行云平台的数据收集
- Compute polling agent则是通过与hypervisor的接口调用定期获取统计数据
- Impi polling agent则是通过ipmi协议收集数据
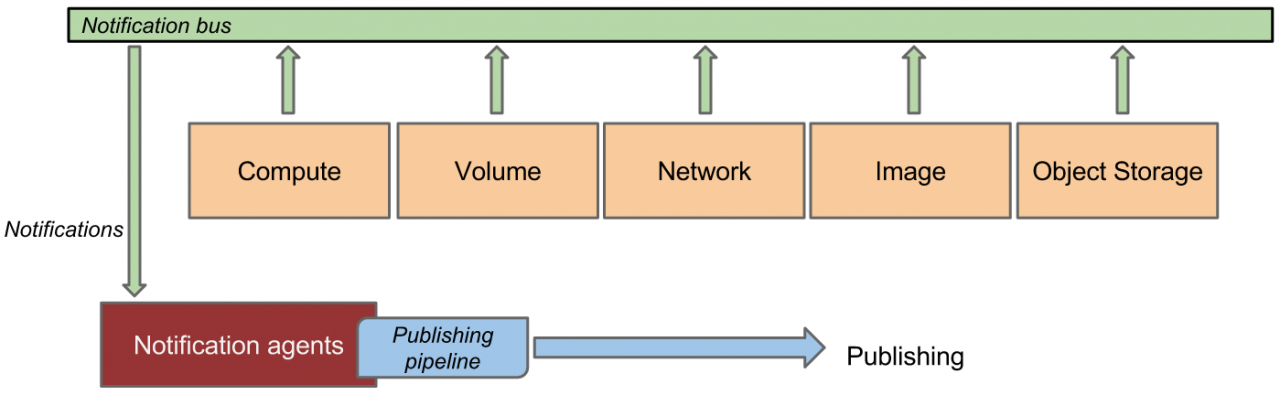
图 2 central polling agent获取监控数据
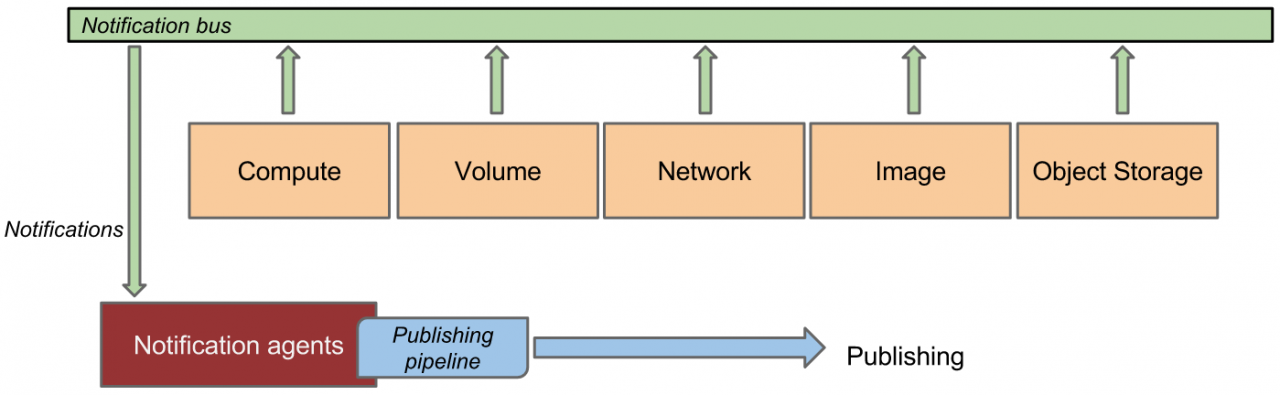
图3 OpenStack services notification 数据收集
b) notification agent:在Mitaka版本中,notification agent通过监听message queue,将message 转化为event和sample并且执行pipeline处理,如图所示。例如虚拟机的CPU利用率,libvirt目前只提供CPUTIME的查询,如果为用户展示CPU利用率要做数据转换,notification agent就会根据pipeline中的定义执行数据转换,并将处理后的数据,通过message queue发送给CCCeilometer collector
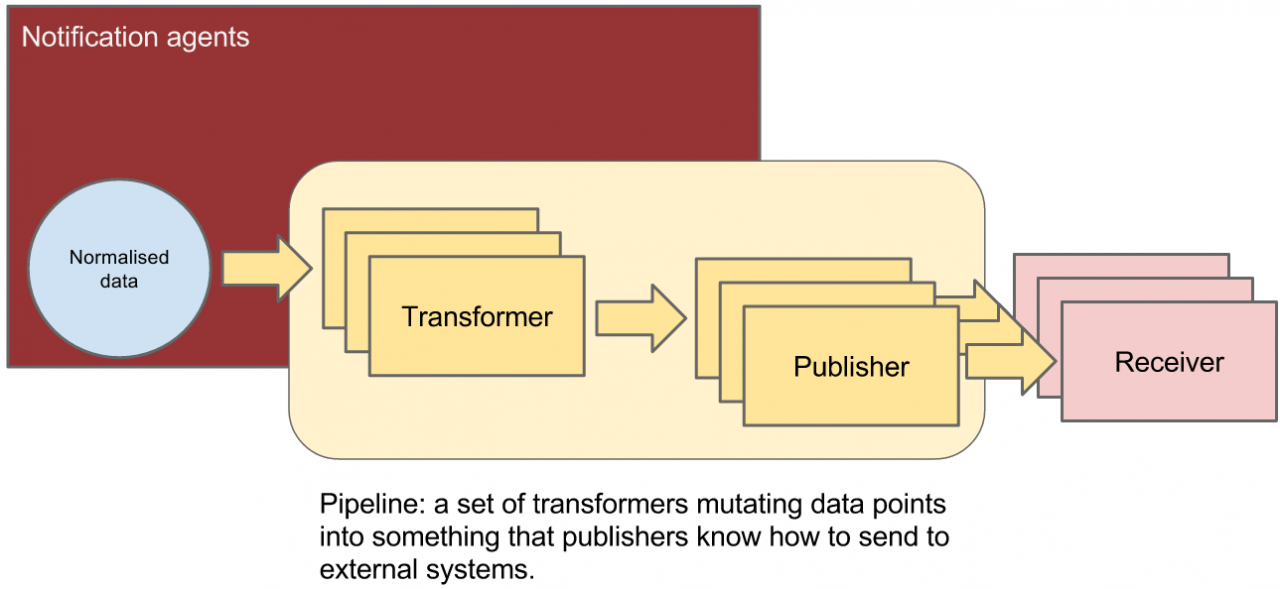
图4 pipeline Manager数据处理
c)Ceilometer collector:ceilometer collector的作用就是将收集到数据存储到存储系统中,CCCeilometer支持多种存储后端:
- 文件系统
- 数据库
|
Driver |
API querying |
API statistics |
|
MongoDB |
Yes |
Yes |
|
MySQL |
Yes |
Yes |
|
PostgreSQL |
Yes |
Yes |
|
HBase |
Yes |
Yes, except groupby & selectable aggregates |
- Gnocchi
- HTTP
对与存储系统的选择是非常关键的,公有云环境中会随着用户和资源的增长数据也会持续增长,这是对云监控服务来说是一个非常大的挑战。下小节,将为描述,我们是如何考量存储系统的。
3、监控数据存储系统抉择
对于计量统计服务来说,存储服务的性能是非常关键的,其中一个要求就是对它的存储量有很大的要求,公有云平台数量很大,每时每刻不断的有数据往系统里面塞。对数据库的吞吐能力要求很高,然后就是对查询性能要求很高。CERN作为OpenStack最大的规模的实践,也采用了MongoDB去做meter数据存储,但是一直以来MongoDB的也一直被诟病,一个存储空间占用,一个随之数据量增多响应时间变大的问题。
3.1 Gnocchi简介
Gnocchi是OpenStack Telemtry的Metric serivce,开始与2015年,目的在与解决CCCeilometer的监控数据存储的性能问题。Gnocchi支持的存储driver有文件系统、Swift、s3、Ceph
官方建议使用ceph,gnocchi对ceph的数据存储做了很多优化。
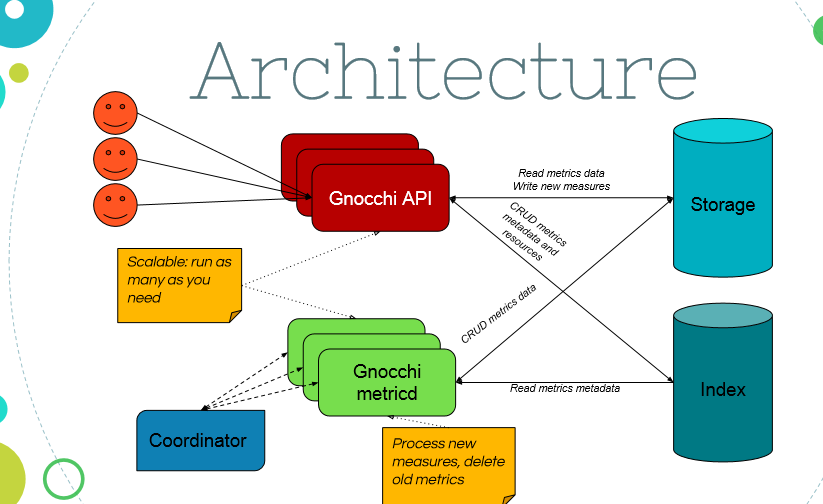
Gnocchi架构如图所示,包含两部分index和storage。Gnocchi API提供restful API接口,接受到数据存储请求时,会创建index在数据库中,并把数据写入临时待处理区,并加入时间戳。
Metricd服务则从待处理数据区获取带有时间戳的数据,将数据追加到统计数据文件中。gnocchi为了节省存储空间在最新版本中加入了压缩算法支持。
对于MongoDB 和Gnocchi的选择,我们做了实际的测试,主要关注两项指标存储空间需求和查询数据响应时间。
3.2 两种方案的测试及分析
方案一:Gocchi + Ceph vs. MonogDB
a) 测试方法
Ceilometer支持配置多个存储后端,修改ceilometer.conf
meter_dispatchers=gnocchi meter_dispatchers=database
数据收集时间:5.5小时
数据收集量:1个compute节点
数据收集频率:1秒
资源:2个vm,1个loadbalancer,1个router
测试环境: all-in-one
Step1:停掉所有的CCCeilometer
Step2:gnocchi清除所有的resource
Step3: 从ceph pool中删除所有的gnocchi相关的objects
rados -p gnocchi rm *
Step4: 从MMMongoDBDBDB中清除CCCeilometer的collection
mongodb > use ceilometer > db.meter.drop() > db.resource.drop()
Step 5: 修改ceilomter配置文件ceilometer.conf
[default] meter_dispatchers=database Meter_dispatchers=gnocchi [database] metering_connection = mongodb://ceilometer:ceilometer@127.0.0.1:27017/ceilometer
Step 6: 设置数据采集周期为1秒
Pipeline.yaml中设置interval参数为1 /etc/neutron/metering-agent.ini # Interval between two metering measures (integer value) measure_interval = 1 # Interval between two metering reports (integer value) report_interval = 1
Step 7: 创建存储数据的Archive policy,并设置粒度为1s
gnocchi archive-policy create -d granularity:1s,points:86400 1days_per_sec +---------------------+-----------------------------------------------------------------+ | Field | Value | +---------------------+-----------------------------------------------------------------+ | aggregation_methods | count, max, sum, min, mean | | back_window | 0 | | definition | - points: 86400, granularity: 0:00:01, timespan: 1 day, 0:00:00 | | name | 1days_per_sec | +---------------------+-----------------------------------------------------------------+
b)测试结果分析
Ceilometer sample 查询时间,跟获取的数据量成正比,当需要查询较多的历史数据时,MongoDB的检索时间会变得更长。
而Gnocchi 检索时间稳定在3~4s,因为Gnocchi的检索时间主要是读取ceph obj,以及解析obj格式
[root@server-31 ~]# time ceilometer sample-list --meter cpu_util -q 'resource_id=0fd02865-c5af-4b86-958c-10fe0ba6f8d5' -l 1000 real 0m2.157s user 0m1.166s sys 0m0.102s [root@server-31 ~]# time ceilometer sample-list --meter cpu_util -q 'resource_id=0fd02865-c5af-4b86-958c-10fe0ba6f8d5' -l 10000 |wc -l 9127 real 0m16.168s user 0m3.455s sys 0m0.272s [root@server-31 ~]# time gnocchi measures show 1dbba325-84cf-4af2-98b8-19e1b8033dd2 |wc -l 9070 real 0m3.202s user 0m2.169s sys 0m0.128s Gnocchi 数据存储量 40MB+

Ceilometer数据存储量3GB+
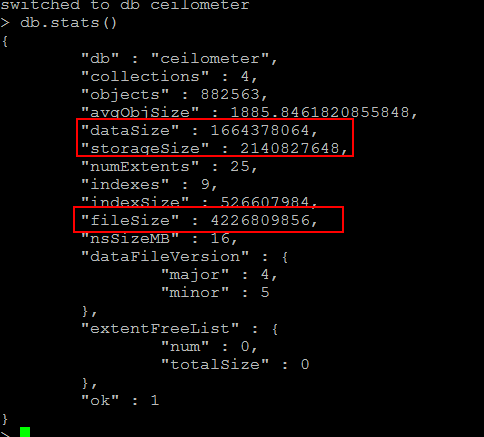
这是一个非常大的数据差距,MongoDBb的数据存储采用的预分配的方式,初始情况下MongoDB的数据空间是128M,当数据量增大时,就会申请256MB空间,以此类推。
而GGGnocchi不同,GGGnocchi对CCCeilometer存储数据做了优化。我们对比了Ceilometer MongoDB存储和Gnocchi存储数据。MongoDB中将CCCeilometer的sample作为value存储在db中。而Gnocchi则采用了不同的方法,仅存储关键的数据:时间戳和sample的value,而对于meter的projectid,userid,start time end time等等,作为index存储在index数据库中。这就大量的节省了存储空间。在存储空间gnocchi表现出来了非常大的优势。
但是非常不幸的事情发生了,我们发现Ceph的读写请求变得延迟非常大。通过我们的分析发现,ceph系统存在大量的小文件读写,影响了ceph系统的性能。Ceph是基于对象的存储系统,并不擅长小文件存储;而gnocchi的数据存储正是产生了大量的小文件。
于是我们又进行了新一轮的测试,即Gnocchi采用本地文件系统。
方案二:Gocchi + filesystem vs. Monogdb
a) 测试方法
Step1: 停止所有ceilometer服务
for i in notification collector polling;do systemctl stop openstack-ceilometer-$i;done
Step2: 清除ceilometer database
>use ceilometer >db.dropDatabase()
Step3:删除所有gnocchi存储的数据
for i in `gnocchi resource list | awk '{print $2}'`;do gnocchi resource delete $i;done
Step4: 停止gnocchi服务
systemctl stop openstack-gnocchi-metricd
Step5: 修改gnocchi.conf使用本地存储
mkdir /tmp/gnocchi-datapath Chown gnocchi:gnocchi -R /tmp/gnocchi-datapath [storage] driver=file file_basepath=/tmp/gnocchi-datapath
Step6: 重启CCCeilometer和 GGGnocchi 服务
数据收集时间2小时44分钟
数据收集量:1个compute节点
数据收集频率:1秒
资源:2个vm,1个loadbalancer,1个router
b) 测试结果
查询响应时间与上次测试结果接近,gnocchi对与大量数据查询具有很强的优势,在这里没有再列出来。
Mongo db 占用总空间约2GB(图中filesize的值)
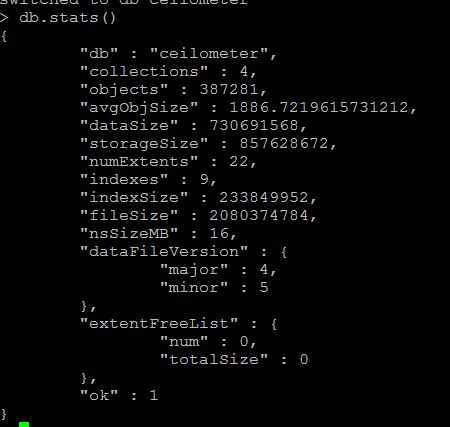
gnocchi 占用空间19MB+
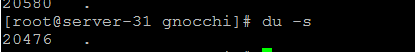
对与存储空间占用,gnocchi文件系统存储采用与ceph object存储一样的存储方式因此在存储空间也非常有优势。
3.3 选型总结
Gnocchi不论是请求响应时间还是存储空间相较于mogodb都有很大的优势,测试结果对比见表格。
|
|
采样频率 |
采样时间 |
空间占用 |
查询响应时间 |
|
Gnocchi + ceph pool |
1s |
5.5小时 |
40MB+ |
3~4s |
|
mongodb |
1s |
5.5小时 |
3GB+ |
16s+ |
|
Gnocchi + filesystem |
1s |
2小时44分 |
19MB+ |
3~4s |
|
mongodb |
1s |
2小时44分 |
2GB+ |
16s+ |
根据Gnocchi官方文档说明,Gnocchi的统计数量是根据云平台要求估算出来的。
目前开放云平台中最低数据收集频率为1分钟,提供30天的数据查询根据官方算法:
粒度: 1分钟
1天points: 60*24
30天: 60*24*30 = 43200points
每个points是8个字节即 43200 * 8 = 345600 B 约为337KB 一个metric数据(也就是收集30天之后才能达到的),而对与Ceph等对象存储服务来讲,并不是很好的选择,尽管gnocchi项目已经针对Ceph做了很多的优化。因此,文件系统模式的存储是比较合适的,对于数据存储可以采用定期备份的方式。
4、 遇到的“坑”
由于数据收集服务在云平台上随着用户量及资源的增多而造成比较大的服务压力,因此OpenStack telemetry必须能满足性能需求。如果与OpenStack其他服务采用相同的message queue和db等服务,将有可能会影响到OpenStack关键服务的性能。
因此采用了独立的message queue用于OpenStack telemetry消息通讯。
然后,我们采用了采用压力测试,监控telemetry数据收集服务状态及message queue的状态。经过压力测试发现gnocchi服务是CPU消耗型,在压力测试的情况下,gnocchi metricd进程会达到单个cpu100%+,单节点CPU达到80%+。
为保证共有云平台服务的质量的稳定性,采取了独立节点部署gnocchi服务。
并对CCCeilometer和GGGnocchi服务做了参数调整,
ccceilometer.conf下列参数避免ceilometer polling agent在同一时间爆发式发送统计数据到消息队列造成队列阻塞。
[DEFAULT] shuffle_time_before_polling_task = 100
Gnocchi.conf 下列参数可以使得metricd进程不会持久占用CPU。
[storage] metric_processing_delay = 60 metric_reporting_delay = 120
根据官方文档说明,ceilometer notification agent如果想要是多节点的HA模式,需要采用tooz做分布式协同,笔者基于项目维护复杂度考虑并未加入tooz作为分布式协同处理,而是采用了单节点的模式并由pacemaker/corosync做resource管理,CCCeilometer提供了batch message处理的方式,那么可以大量减少消息处理带来的性能问题。通过检测message queue中的阻塞数据,在1秒的数据采集间隔中基本上都保留在500以内。
但是一切并不如想象中那么顺利,很快遇到了新的问题,即使notification agent采用了单节点模式,在做VM CPU压力测试时发现,收集到数据并不正确。通过分析ceilometer notification agent code发现。ccceilometer notification 的data transform,是采用的进程内存做历史数据存储,也就是说即使是单节点多进程的情况,历史数据也是分别处理的,在这里简单介绍一下CPU利用率计算方法。libvirt不支持CPU利用率的直接获取,只能获取CPU time来计算出实际使用率。计算的公式为:
首先得到一个周期差:CPU_time_diff = cpuTimenow — cpuTimet seconds ago
然后根据这个差值计算实际使用率:%CPU = 100 × CPU_time_diff / (t × nr_cores × 109)
这就意味着间隔1秒的数据并未能正确被对应的notification agent获取到并转化出CPU利用率。所以关于notification agent在不启用协同tooz的情况下只采用单进程的方式工作,要么就要放弃所有的数据转化部分,只使用CCCeilometer的收集和存储能力。
5、告警服务
aodh是从CCCeilometer中独立出来的仅负责用于告警服务。Aodh也支持了基于gnocchi统计数据的告警设置。
Aodh支持如下类型的告警触发协议类型:
- HTTP: 发送http request到指定的URL
- HTTPS: 发送https request到指定的URL
- LOG:notification日志
- TEST:测试用处
- Trust + HTTP/HTTPS:加入了keystone身份认证
告警通知可以采用Webhook去实现,从而达到可以发送邮件,短信,微信等方式的用户实时告警。
6、我们的改进
作为公有云平台服务,单单功能实现是不足以满足需求的,需要考虑到应对公有云大规模场景的性能问题。对此,云极星创针对OpenStack Telemetry做个部分定制功能。
首先,我们对数据量做了优化,云监控的目标是为云平台用户提供对用户资源监控和告警。因此我们通过定制polling agent的pollster list,减少数据量处理和传输。
Message Queue和Database是云平台核心的支撑组件,为了避免大量数据计量服务影响到云平台核心业务性能,我们采用了单独的Message Queue和Database用于云监控服务。
为了保证云监控服务运行,我们从运维层面也做了监控,例如对云监控服务健康状态、服务响应时间、消息队列状态、数据库慢查询、服务节点CPU、内存、磁盘、网络流量等进行监控。
Gnocchi服务开发时间尚短目前位置没有大规模使用的用例,我们在云监控平台开发中也遇到功能不满足需求的情况,例如,监控数据获取gnocchi目前仅支持针对单个metric的数据获取,也就是说如果想要做成面板模式的展示意味着要同时发送多个API请求去获取数据,这对于UI是有性能影响的。云极星创对这些问题做了二次开发,也会计划把代码回馈给社区。
7、写在最后
云极星创通过Openstack Telemetry项目实现云监控平台过程中遇到的各种“坑”,越发觉得即使是Openstack作为最活跃云计算开源社区依然距离商业化路途依然尚远。因此,我们会在增强服务稳定性和高性能方面做出更多的努力和尝试,并乐于分享和贡献到开源社区。
参考文档
- Ceilometer监控指标
- Gnocchi文档
- Aodh API
- Aodh DB支持
- CERN 参考架构
- Installation and turial guide
- Telemetry admin guide
作者简介
任敏敏,云极星创高级开发工程师,专注云平台开发工作,在OpenStack领域有多年开发经验, OpenStack社区项目的开发人员,具有较丰富的OpenStack开发和运维经验,原IBM云计算部门软件开发工程师。
转自 http://www.infoq.com/cn/articles/how-to-implement-cloud-monitoring-alarm-service