 Linuxeden开源社区
Linuxeden开源社区摘要: TensorFlow入门介绍
TensorFlow入门
本文将初步向码农和程序媛们介绍如何使用TensorFlow进行编程。在阅读之前请先 安装TensorFlow,此外为了能够更好的理解本文的内容,阅读之前需要了解一点以下知识:
- python基本编程。能看得懂python代码,最好能使用脚本工具或pycharm之类的IDC编写代码。
- 至少有一点数组的概念。
- 最理想的状态是具备机器学习的基础知识。不过如果在阅读之前没有了解过任何机器学习相关的知也无大碍,可以把本文作为了解机器学习的开端。后面会另开一篇用MNIST了解机器学习的基础知识。
TensorFlow提供种类繁多的API接口,其中TensorFlow Core是最低层级的接口,为开发TensorFlow提供基础支持。官方推荐把TensorFlow Core用作机器学习研究以及相关的数据建模。除了TensorFlow Core之外还有更高抽象的API接口,这些API接口比TensorFlow Core更易于使用、更易于快速实现业务需求。例如 tf.contrib.learn 接口,它提供管理数据集合、进行数据评估、训练、推演等功能。在使用TensorFlow开发的过程中需要特别注意,以 contrib 开头的API接口依然还在不断完善中,很有可能在未来某个发行版本中进行调整或者直接取消。
本文首先介绍TensorFlow Core,然后会演示如何使用 tf.contrib.learn 实现简单的建模。了解TensorFlow Core是为了让开发者理解在使用抽象接口时底层是如何工作的,以便于在训练数据时创建更合适的模型。
TensorFlow
TensorFlow的基础数据单元是张量(tensor)。一个张量认为是一组向量的集合,从数据结构的角度来理解这个集合等价于一组数值存储在1到多个队列中(张量没办法几句话说得清楚,想要了解去谷哥或者度妞搜索“张量分析”,可以简单想象成一个多维度的数组)。一个张量的阶表示了张量的维度,下面是一些张量的例子:
3 # 0阶张量,可以用图形[]来表示
[1. ,2., 3.] # 1阶张量,是一个图形为[3]的向量
[[1., 2., 3.], [4., 5., 6.]] # 2阶张量,是一个图形为[2,3]的矩阵
[[[1., 2., 3.]], [[7., 8., 9.]]] # 图形为[2,1,3]的三阶张量
TensorFlow Core教程
导入TensorFlow
下面是导入TensorFlow包的标准方式:
import tensorflow as tf通过python的方式导入之后, tf 提供了访问所有TensorFlow类、方法和符号的入口。
图计算(Computational Graph)
TensorFlow Core的编程开发可以看就做2个事:
- 构建计算图。(建模)
- 运行计算图。(执行)
图(graph,也可以叫连接图)表示由多个点链接而成的图。本文中的图指的是TensorFlow建模后运算的路径,可以使用TensorBoard看到图的整个形态。
节点(node)表示图中每一个点,这些点都代表了一项计算任务。
所以简而言之:编程 TensorFlow Core 就是事先安排好一系列节点的计算任务,然后运行这些任务。
下面我们先构建一个简单的图,图中的节点(node)有0或多个张量作为输入,并产生一个张量作为输出。一个典型的节点是“常量”(constant)。TensorFlow的常量在构建计算模型时就已经存在,在运行计算时并不需要任何输入。下面的代码创建了2个浮点常量值常量 node1 和 node2:
node1 = tf.constant(3.0, tf.float32)
node2 = tf.constant(4.0) # also tf.float32 implicitly
print(node1, node2)运行后会打印输出:
Tensor("Const:0", shape=(), dtype=float32) Tensor("Const_1:0", shape=(), dtype=float32)观察这个打印的结果会发现,它并不是按照预想的那样输出 3.0 或 4.0 的值。这里输出的是一个节点的对象信息。因为到这里还没有执行第二项工作——运行计算模型图。只有在运行时,才会使用到节点真实的值 3.0 和4.0。为了进行图运算需要创建一个会话(session),一个会话封装了TensorFlow运行库的各种控制方法和状态量(context)。
下面的代码会创建一个会话(session)对象实例,然后执行 run 方法来进行模型计算:
sess = tf.Session()
print(sess.run([node1, node2]))运行后我们会发现,打印的结果是3.0和4.0:
[3.0, 4.0]然后,对 node1 和 node2 进行和运算,这个和运算就是图中的运算模型。下面的代码是构建一个 node1 、 node2 进行和运算, node3 代表和运算的模型,构建完毕后使用 sess.run 运行:
node3 = tf.add(node1, node2)
print("node3: ", node3)
print("sess.run(node3): ",sess.run(node3))运行后会输出了以下内容:
node3: Tensor("Add_2:0", shape=(), dtype=float32)
sess.run(node3): 7.0到此,完成了TensorFlow创建图和执行图的过程。
前面提到TensorFlow提供了一个名为TensorBoard的工具,这个工具能够显示图运算的节点。下面是一个TensorBoard可视化看到计算图的例子:
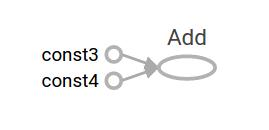
这样的常量运算结果并没有什么价值,因为他总是恒定的产生固定的结果。图中的节点能够以参数的方式接受外部输入——比如使用占位符。占位符可以等到模型运行时再使用动态计算的数值:
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
adder_node = a + b # + 可以代替tf.add(a, b)构建模型上面这3行代码有点像用一个function或者一个lambda表达式来获取参数输入。我们可以在运行时输入各种各样的参数到图中进行计算:
print(sess.run(adder_node, {a: 3, b:4.5}))
print(sess.run(adder_node, {a: [1,3], b: [2, 4]}))输出结果为:
7.5
[ 3. 7.]在TensorBoard中,显示的计算图为:
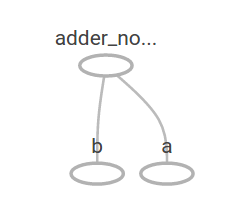
我们可以使用更复杂的表达式来增加计算的内容:
add_and_triple = adder_node * 3.
print(sess.run(add_and_triple, {a: 3, b:4.5}))计算输出:
22.5TensorBoard中的显示:
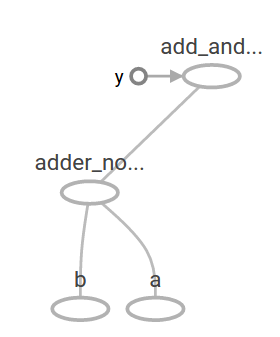
在机器学习中一个模型通常需要接收各种类型的数据作为输入。为了使得模型可以不断的训练通常需要能够针对相同的输入修改图的模型以获取新的输出。变量(Variables)可以增加可训练的参数到图中,他们由指定一个初始类型和初始值来创建:
W = tf.Variable([.3], tf.float32)
b = tf.Variable([-.3], tf.float32)
x = tf.placeholder(tf.float32)
linear_model = W * x + b前面已经提到在调用 tf.constant 时会初始化不可变更的常量。 而这里通过调用 tf.Variable 创建的变量不会被初始化,为了在TensorFlow运行之前(sess.run执行模型运算之前)初始化所有的变量,需要增加一步 init 操作:
init = tf.global_variables_initializer()
sess.run(init)可以通过重载 init 方式来全局初始化所有TensorFlow图中的变量。在上面的代码中,在我们调用 sess.run 之前,所有的变量都没有初始化。
下面的 x 是一个占位符,{x:[1,2,3,4]} 表示在运算中把x的值替换为[1,2,3,4]:
print(sess.run(linear_model, {x:[1,2,3,4]}))输出:
[ 0. 0.30000001 0.60000002 0.90000004]现在已经创建了一个计算模型,但是并不清晰是否足够有效,为了让他越来越有效,需要对这个模型进行数据训练。下面的代码定义名为 y 的占位符来提供所需的值,然后编写一个“损益功能”(loss function)。
一个“损益功能”是用来衡量当前的模型对于想达到的输出目标还有多少距离的工具。下面的例子使用线性回归作为损益模型。回归的过程是:计算模型的输出和损益变量(y)的差值,然后再对这个差值进行平方运算(方差),然后再把方差的结果向量进行和运算。下面的代码中, linear_model - y 创建了一个向量,向量中的每一个值表示对应的错误增量。然后调用 tf.square 对错误增量进行平方运算。最后将所有的方差结果相加创建一个数值的标量来抽象的表示错误差异,使用 tf.reduce_sum来完成这一步工作。如下列代码:
# 定义占位符
y = tf.placeholder(tf.float32)
# 方差运算
squared_deltas = tf.square(linear_model - y)
# 定义损益模型
loss = tf.reduce_sum(squared_deltas)
# 输出损益计算结果
print(sess.run(loss, {x:[1,2,3,4], y:[0,-1,-2,-3]}))运算之后的差异值是:
23.66可以通过手动将 W 和 b 的值修改为-1和1降低差异结果。TensorFlow中使用 tf.Variable 创建变量,使用 tf.assign 修改变量。例如 W=-1 、b=1 才是当前模型最佳的值,可以像下面这样修改他们的值:
fixW = tf.assign(W, [-1.])
fixb = tf.assign(b, [1.])
sess.run([fixW, fixb])
print(sess.run(loss, {x:[1,2,3,4], y:[0,-1,-2,-3]}))修改之后的最终输出结果为:
0.0
tf.train 接口
机器学习的完整过程超出了本文的范围,这里仅说明训练的过程。TensorFlow提供了很多优化器来逐渐(迭代或循环)调整每一个参数,最终实现损益值尽可能的小。最简单的优化器之一是“梯度递减”(gradient descent),它会对损益计算模型求导,然后根据求导的结果调整输入变量的值(W和b),最终目的让求导的结果逐渐趋向于0。手工进行编写求导运算非常冗长且容易出错,TensorFlow还提供了函数 tf.gradients 实现自动求导过程。下面的例子展示了使用梯度递减训练样本的过程:
# 设定优化器,这里的0.01表示训练时的步进值
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)
sess.run(init) # 初始化变量值.
for i in range(1000): # 遍历1000次训练数据,每次都重新设置新的W和b值
sess.run(train, {x:[1,2,3,4], y:[0,-1,-2,-3]})
print(sess.run([W, b]))这个模式的运算结果是:
[array([-0.9999969], dtype=float32), array([ 0.99999082], dtype=float32)]现在我们已经完成机器学习的整个过程。虽然进行简单的线性回归计算并不需要用到太多的TensorFlow代码,但是这仅仅是一个用于实例的案例,在实际应用中往往需要编写更多的代码实现复杂的模型匹配运算。TensorFlow为常见的模式、结构和功能提供了更高级别的抽象接口。
一个完整的训练过程
下面是根据前文的描述,编写的完整线性回归模型:
import numpy as np
import tensorflow as tf
# 模型参数
W = tf.Variable([.3], tf.float32)
b = tf.Variable([-.3], tf.float32)
# 模型输入
x = tf.placeholder(tf.float32)
# 模型输出
linear_model = W * x + b
# 损益评估参数
y = tf.placeholder(tf.float32)
# 损益模式
loss = tf.reduce_sum(tf.square(linear_model - y)) # 方差和
# 优化器
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)
# 训练数据
x_train = [1,2,3,4]
y_train = [0,-1,-2,-3]
# 定义训练的循环
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init) # reset values to wrong
for i in range(1000):
sess.run(train, {x:x_train, y:y_train})
# 评估训练结果的精确性
curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x:x_train, y:y_train})
print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))运行后会输出:
W: [-0.9999969] b: [ 0.99999082] loss: 5.69997e-11这个复杂的程序仍然可以在TensorBoard中可视化呈现:
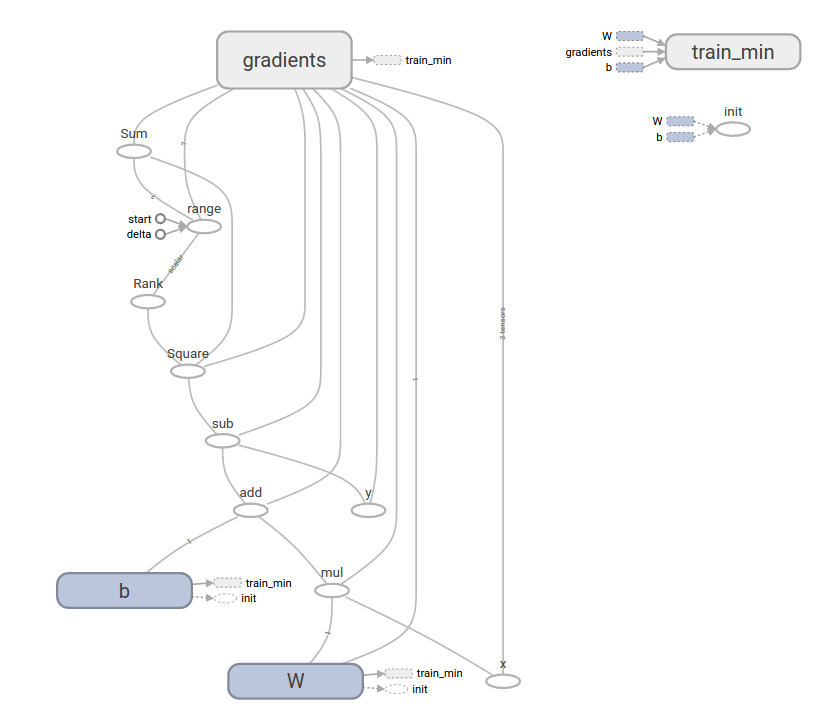
tf.contrib.learn
前面已经提到,TensorFlow除了TensorFlow Core之外,为了便于业务开发还提供了很多更抽象的接口。tf.contrib.learn 是TensorFlow的一个高级库,他提供了更加简化的机器学习机制,包括:
- 运行训练循环
- 运行评估循环
- 管理数据集合
- 管理训练数据
tf.contrib.learn 定义了一些通用模块。
基本用法
先看看使用 tf.contrib.learn 来实现线性回归的方式。
import tensorflow as tf
# NumPy常用语加载、操作、预处理数据.
import numpy as np
# 定义一个特性列表features。
# 这里仅仅使用了real-valued特性。还有其他丰富的特性功能
features = [tf.contrib.layers.real_valued_column("x", dimension=1)]
# 一个评估者(estimator)是训练(fitting)与评估(inference)的开端。
# 这里预定于了许多类型的训练评估方式,比如线性回归(linear regression)、
# 逻辑回归(logistic regression)、线性分类(linear classification)和回归(regressors)
# 这里的estimator提供了线性回归的功能
estimator = tf.contrib.learn.LinearRegressor(feature_columns=features)
# TensorFlow提供了许多帮助类来读取和设置数据集合
# 这里使用了‘numpy_input_fn’。
# 我们必须告诉方法我们许多多少批次的数据,以及每次批次的规模有多大。
x = np.array([1., 2., 3., 4.])
y = np.array([0., -1., -2., -3.])
input_fn = tf.contrib.learn.io.numpy_input_fn({"x":x}, y, batch_size=4,
num_epochs=1000)
# ‘fit’方法通过指定steps的值来告知方法要训练多少次数据
estimator.fit(input_fn=input_fn, steps=1000)
# 最后我们评估我们的模型价值。在一个实例中,我们希望使用单独的验证和测试数据集来避免过度拟合。
estimator.evaluate(input_fn=input_fn)运行后输出:
{'global_step': 1000, 'loss': 1.9650059e-11}
自定义模型
tf.contrib.learn 并不限定只能使用它预设的模型。假设现在需要创建一个未预设到TensorFlow中的模型。我们依然可以使用tf.contrib.learn保留数据集合、训练数据、训练过程的高度抽象。我们将使用我们对较低级别TensorFlow API的了解,展示如何使用LinearRegressor实现自己的等效模型。
使用 tf.contrib.learn 创建一个自定义模型需要用到它的子类 tf.contrib.learn.Estimator 。而 tf.contrib.learn.LinearRegressor 是 tf.contrib.learn.Estimator 的子类。下面的代码中为 Estimator 新增了一个 model_fn 功能,这个功能将告诉 tf.contrib.learn 如何进行评估、训练以及损益计算:
import numpy as np
import tensorflow as tf
# 定义一个特征数组,这里仅提供实数特征
def model(features, labels, mode):
# 构建线性模型和预设值
W = tf.get_variable("W", [1], dtype=tf.float64)
b = tf.get_variable("b", [1], dtype=tf.float64)
y = W*features['x'] + b
# 损益子图
loss = tf.reduce_sum(tf.square(y - labels))
# 训练子图
global_step = tf.train.get_global_step()
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = tf.group(optimizer.minimize(loss),
tf.assign_add(global_step, 1))
# ModelFnOps方法将创建我们自定义的一个抽象模型。
return tf.contrib.learn.ModelFnOps(
mode=mode, predictions=y,
loss=loss,
train_op=train)
estimator = tf.contrib.learn.Estimator(model_fn=model)
# 定义数据集
x = np.array([1., 2., 3., 4.])
y = np.array([0., -1., -2., -3.])
input_fn = tf.contrib.learn.io.numpy_input_fn({"x": x}, y, 4, num_epochs=1000)
# 训练数据
estimator.fit(input_fn=input_fn, steps=1000)
# 评估模型
print(estimator.evaluate(input_fn=input_fn, steps=10))运行后输出:
{'loss': 5.9819476e-11, 'global_step': 1000}
接下来做什么
阅读了到这里,你应该初步了解如何在TensorFlow中进行开发和编码。但是如果你刚踏入机器学习的领域,就算很仔细的看了本文,对于如何使用TensorFlow进行机器学习基本上还是懵逼的。请继续阅读《MNIST 机器学习入门》,文章给出了一个完整的机器学习建模案例,适合零知识入门机器学习。
转自 https://my.oschina.net/chkui/blog/886521